Airflow in Action: How DoorDash Scaled for Data and ML Engineering
6 min read |
By its own estimates, DoorDash operates one of the largest Apache Airflow® deployments in the industry. In their session Scaling and Unifying Multiple Airflow Instances at the Airflow Summit, Software Engineers Chirag Todarka and Alvin Zhang explained how a single monolithic instance became an operational bottleneck. They demonstrated how they solved it by building the Orchestration Frederator, a unifying layer that enables horizontal scaling across multiple Airflow instances.
The session covers the technical architecture, the migration strategy, and the operational gains the team achieved.
One Instance. Thousands of Dags. A Mandate to Scale.
The infrastructure team owns the Airflow platform at DoorDash. Data engineers, ML engineers, and other internal users own the Dags. That separation of ownership worked well at manageable scale. But DoorDash had a clear business mandate: support significantly more use cases without increasing the size of the infrastructure team.
The team explored the obvious path first: keep adding pipelines to the existing cluster. In theory, Apache Airflow supports it, but in practice, running Airflow at high scale requires specialist knowledge and ongoing infrastructure maintenance. When running thousands of Dags, scheduler memory pressure increases, Dag parsing slows, the API server becomes less responsive, and metadata DB connections multiply. Reliability can degrade in ways that are difficult to diagnose and even harder to fix.
A monolithic deployment also creates upgrade risk. Every Airflow version bump, Python package dependency change, or internal operator update gets pushed to the entire fleet simultaneously. That reality makes teams cautious and slow. It was a pattern Chirag and Alvin recognized not just at DoorDash, but across other companies they spoke with.
Break the Monolith. But Don't Create a Mess.
The decision was taken to split the single large cluster into smaller, tiered instances. DoorDash categorized pipelines by importance to the business, with high-criticality workloads on dedicated top-tier instances and lower-criticality workloads distributed across other tiers. The approach delivers scalability, reliability, and isolation for staged rollouts.
But fragmentation introduced new problems. Pipeline owners no longer knew which instance to check. Cross-instance Dag dependencies became difficult to manage. Pipelines needed to move between tiers dynamically as business priorities changed. Without a unifying layer, management would become much more complex.
Enter Frederator: One Interface to Rule Them All
The Orchestration Frederator sits above all of DoorDash’s Airflow instances and acts as a single point of interaction. At its core is a centralized database that continuously syncs a mapping of which pipeline lives in which instance. This powers three things:
- A unified UI that redirects users to the correct Airflow instance on search
- Cross-instance Dag dependencies via a sensor that queries Frederator to locate and check Dag completion status
- Failure alerts that include direct links to the correct Airflow UI, keeping the debugging experience consistent for all pipeline owners.
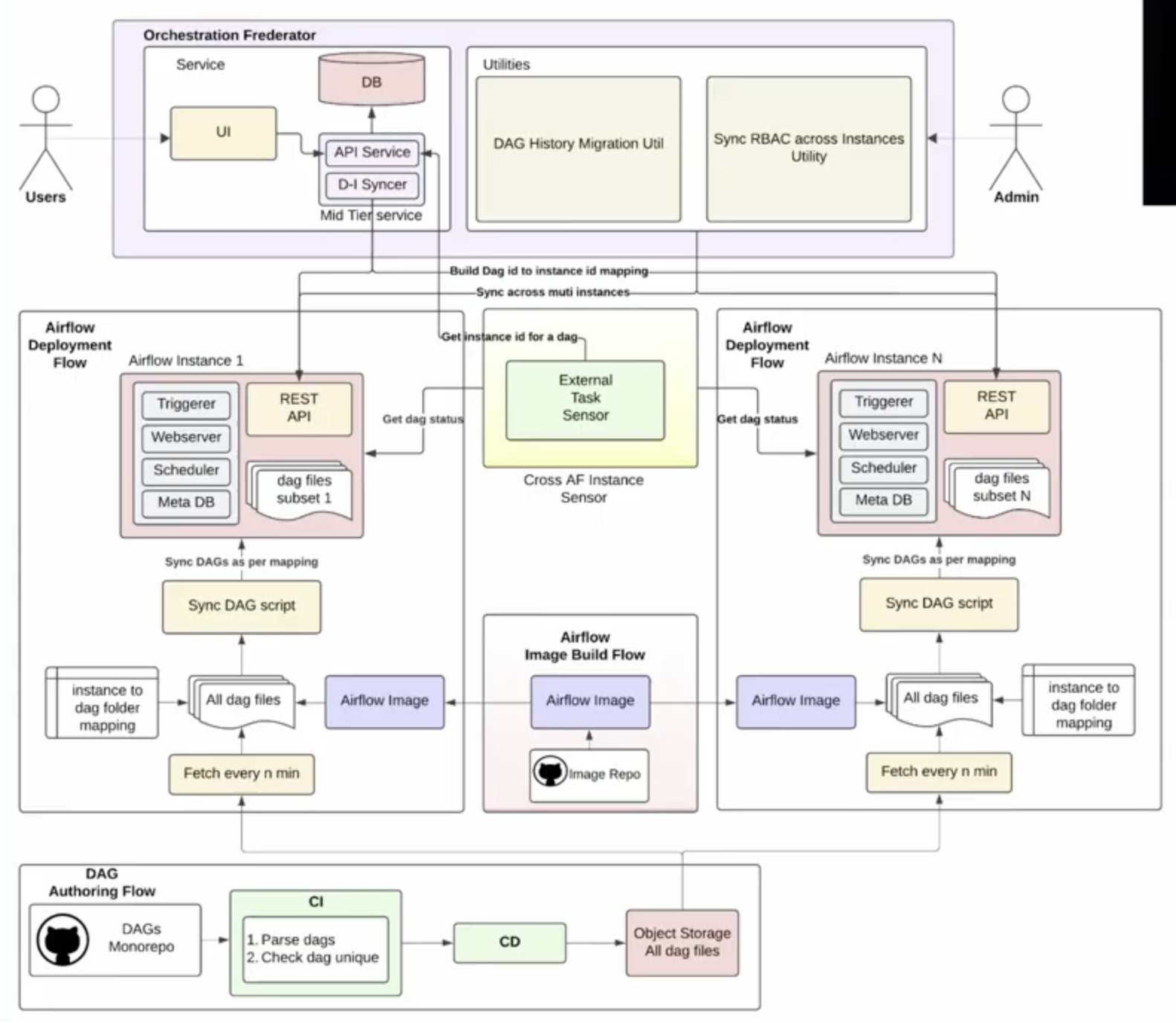
Figure 1: Orchestration Frederator high-level architecture, showing how a central routing layer unifies multiple independent Airflow deployments. Image source.
Migration uses a dual-hosting approach: during a move, a Dag runs in both instances with one enabled and one disabled, while an open source utility carries over run history to prevent duplicates.
The Results: Scale Without Chaos
The platform now scales horizontally by adding instances behind Frederator with no changes required for Dag owners.
- Each instance runs well below capacity, which has significantly improved reliability.
- Upgrades roll out tier by tier, giving the infrastructure team time to catch issues before they reach critical workloads.
- Management stays consistent across all instances because the infrastructure team controls deployments end to end.
In their session, Chirag and Alvin cover the architecture in detail, discuss where the system still has room to grow, and share lessons learned from operating at a scale most organizations are heading toward but few have reached. Watch the full replay to see how they built it.
What DoorDash Built, Astro Delivers Out of the Box
The engineering investment DoorDash made to scale Airflow is real. Their solution is impressive. and required great expertise. Astro, the fully managed Airflow service, delivers all these benefits out-of-the-box at the click of a button and with no need to maintain complex infrastructure. Additionally to easily running hundreds of Airflow deployments with full observability, Astro offers:
- Elastic auto-scaling: Workers scale automatically every 10 seconds based on queued and running tasks, absorbing burst workloads without manual intervention. Set minimum worker counts to zero so queues only consume resources when active.
- Task-optimized worker queues: Route workloads to separate queues, each with its own compute size, scaling behavior, and worker type, from 1 vCPU to 32 vCPU. Right-size compute for every workload within a single deployment.
- High availability across availability zones: Run production workloads across multiple availability zones with a 99.5% uptime SLA. Dag execution continues without interruption if a node or zone goes down.
- Cross-region disaster recovery: When a region goes down, your pipelines keep running. Astro continuously replicates your metadata database and task logs to a standby cluster in a separate region. A single click from the Astro UI initiates failover, with RTO under 1 hour and RPO under 15 minutes. No custom architecture to build, no replication logic to write.
- Multi-cloud deployment: Deploy on AWS, Azure, or Google Cloud across 55+ regions. For teams with stricter requirements, Astro Private Cloud provides dedicated single-tenant infrastructure in your own cloud environment.
- Remote execution: Run tasks in your own infrastructure while Astro handles orchestration. Agents use only outbound connections, so your data, code, secrets, and logs stay within your environment.
- Astro Private Cloud: A single unified control plan to manage several Airflow deployments in any cluster across regions or VPCs. Enterprise-grade Airflow, within your own environment without building your own Federator.
- Real-time pipeline lineage: Lineage is extracted automatically from Airflow tasks as pipelines execute, giving you end-to-end visibility across upstream and downstream dependencies without building a separate monitoring layer.
DoorDash's Orchestration Frederator is a testament to what a strong engineering team can build on top of Airflow. Astro packages that scalability, reliability, and operational control as a managed service, so your team can focus on pipelines, not platform engineering and Kubernetes maintenance. You can get started now with Astro now at no cost.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.