Abstraction with DAG Factory: From Excel to Minecraft
11 min read |
In Part I of this series, we discussed the rise of abstraction in data orchestration, from Ada Lovelace's Note G to AI-assisted Dag authoring in the Astro IDE. Ada faced a universal challenge: how to translate human intent into machine instructions. That challenge persists today.
In this second part, we explore the middle ground between full code and full abstraction: configuration-based authoring with DAG Factory. This approach uses an imperative structure with explicit tasks, but employs declarative syntax, enabling YAML-based rather than Python-based authoring. This approach serves two audiences: data practitioners who prefer YAML over Python, and teams who want to build advanced abstraction use cases. This article explains when and why to choose this level of abstraction, and provides examples of what’s possible, such as generating Dags from Excel files, and even from within Minecraft.
Bridging code and config
It is late afternoon in the drawing-room of Ockham Park, Surrey.
By the window sits Ada Lovelace. Candles flicker low. On her desk lie two items: a sheet of diagrams and a slender column of notations she has made for the Analytical Engine. In one hand she holds a pencil. In the other, a slip of paper that bears the words poetical science.
She envisions a machine that might follow instructions, transforming symbols into meaning and ideas into action. Poetical science combines the imagination and intuition of poetry with the logic and reason of mathematics and science. It bridges disciplines through vision and imagination.
Decades later, in a sunlit modern office, a data scientist opens a spreadsheet. Column A contains Dag names. Column B contains commands. The data scientist runs a short Python script. Within seconds, dozens of Apache Airflow Dags emerge, automatically translated using DAG Factory. This project showcases poetical science: it bridges the gap between disciplines, connecting code and configuration.
About DAG Factory
DAG Factory is an open-source library maintained by Astronomer that dynamically generates Airflow DAGs from YAML files. It occupies the middle ground between fully code-based authoring and high-level declarative templates, combining the flexibility of Python with the simplicity of configuration.
Instead of writing every task in Python, you define your pipeline structure in YAML and reference existing Python functions or SQL files for the actual business logic. This makes Airflow approachable for non-engineers while keeping all of its power for developers.
Best practice: separate orchestration and business logic. To some extent, you can also define business logic right inside the YAML definition, like defining the SQL query when using theSQLExecuteQueryOperatoror the bash command when using theBashOperator. However, when using DAG Factory, Astronomer recommends separating orchestration from business logic whenever applicable.
Because you declare what to build but still specify how it should be built step by step, configuration-based authoring bridges the declarative syntax of YAML with the imperative nature of Airflow's operators and dependencies.
DAG Factory basics
DAG Factory requires two main components for configuration-based authoring: the YAML definition and the generator script. The YAML definition specifies your Dag structure. The generator script uses the DAG Factory library to locate your YAML file and generate the actual Airflow Dags from it. This approach gives you full control over the generation process and supports extensive customization for advanced use cases.
DAG Factory supports Apache Airflow 3, modern scheduling features like assets, traditional operators, and the modern TaskFlow API.
It also supports complex Python objects directly in your YAML configuration files through a generalized object syntax. You can represent objects such as datetime, timedelta, Airflow timetables, assets, and even Kubernetes objects in a declarative, readable format.
The following example shows a basic YAML configuration that defines dependencies, uses task groups, and mixes traditional operators with the TaskFlow API:
basic_example_dag:
default_args:
owner: "astronomer"
start_date: 2025-09-01
description: "Basic example DAG"
tags: ["demo", "etl"]
schedule: "@hourly"
task_groups:
extract:
tooltip: "data extraction"
tasks:
extract_data_from_a:
decorator: airflow.sdk.task
python_callable: include.tasks.basic_example_tasks._extract_data
task_group_name: extract
extract_data_from_b:
decorator: airflow.sdk.task
python_callable: include.tasks.basic_example_tasks._extract_data
task_group_name: extract
store_data:
decorator: airflow.sdk.task
python_callable: include.tasks.basic_example_tasks._store_data
processed_at: "{{ logical_date }}"
data_a: +extract_data_from_a
data_b: +extract_data_from_b
dependencies: [extract]
validate_data:
operator: airflow.providers.standard.operators.bash.BashOperator
bash_command: "echo data is valid"
dependencies: [store_data]Note how +extract_data_from_a and +extract_data_from_b are used to pass the return value of the extract tasks to the store_data task, and how Jinja templating ({{ logical_date }}) is used to insert the logical date.
The generator script, the second component, can parse individual YAML configurations. However, the most pragmatic approach parses all YAML files in your dags/ folder recursively:
# keep import to ensure the dag processor parses the file
from airflow.sdk import dag
from dagfactory import load_yaml_dags
load_yaml_dags(globals_dict=globals())In this particular case, we need to add the dag import as an indicator for Airflow, to not skip this file during parsing.
When searching for dags inside the dag bundle, Airflow only considers Python files that contain the stringsairflowanddag(case-insensitively) as an optimization. Because of these optimizations, you might need to add thedagimport to ensure your file is parsed. To consider all Python files instead, disable theDAG_DISCOVERY_SAFE_MODEconfiguration flag.
For a more comprehensive way to learn about how to use DAG Factory, read our DAG Factory tutorial.
Configuration as a universal language
Ada Lovelace imagined translating ideas into instructions, DAG Factory imagines translation from many sources into executable workflows. The power is YAML's simplicity. Writing Python code programmatically is hard. Managing imports, handling indentation, escaping strings, maintaining syntax, it's a minefield of edge cases.
Once orchestration becomes configuration-driven, the authoring interface can be anything that outputs YAML.
The following two examples, one playful, one practical, illustrate how far this flexibility can go.
Building DAGs in Minecraft
Minecraft probably needs no introduction. It ranks among the world's best-selling computer games and has its own Hollywood movie. Minecraft has become a powerful educational tool for developers and programmers learning Java and software development. Over 35 million teachers and students across 115 countries use the Minecraft Education Edition.
Combining Apache Airflow and Minecraft by building Dags within the game may not sound like it has significant business value. However, it powerfully demonstrates why DAG Factory proves valuable for abstraction.
I developed a Minecraft plugin called Mineflow, which uses PaperMC, a performance-optimized Minecraft server that includes a plugin API for extensive customization. Mineflow allows you to orchestrate Dags in Minecraft by placing blocks:
- Diamond blocks represent Dags.
- Gold blocks represent Python tasks.
- Iron blocks represent Bash tasks.
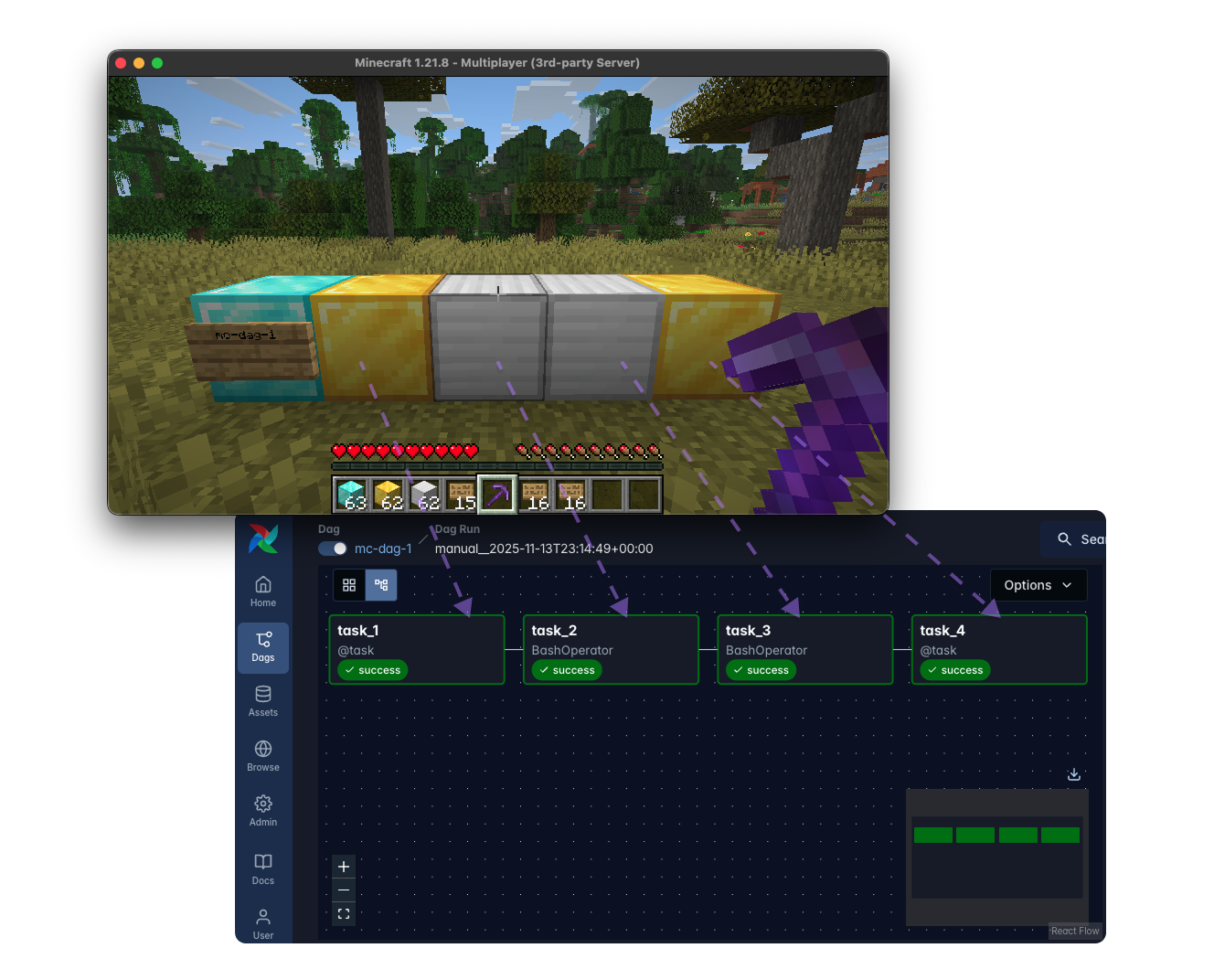
When a player constructs a pattern, Mineflow converts it into YAML. DAG Factory then immediately translates this YAML into live Airflow Dags. To detect whether blocks connect as a pipeline, I used the Breadth-First Search (BFS) algorithm. Players can also rename Dags by placing a sign on the diamond block. The YAML files sync in real-time to reflect any changes, such as adding or removing tasks from a pipeline.
DAG Factory makes this possible by generating YAML rather than Python code, which significantly simplifies the process. With SnakeYAML, I dumped a Map as YAML:
private void writeDagToFile(Map<String, Object> dagConfig, File file) throws IOException {
DumperOptions options = new DumperOptions();
options.setDefaultFlowStyle(DumperOptions.FlowStyle.BLOCK);
options.setPrettyFlow(true);
options.setIndent(2);
Yaml yaml = new Yaml(options);
try (FileWriter writer = new FileWriter(file)) {
yaml.dump(dagConfig, writer);
}
}This means that generating the Dag required describing it simply as a Map in Java, for example:
Map<String, Object> taskConfig = new LinkedHashMap<>();
if (task.isGold()) {
taskConfig.put("decorator", "airflow.sdk.task");
taskConfig.put("python_callable", "include.mineflow.log");
taskConfig.put("message", "Gold task at location " + task.getId());
} else {
taskConfig.put("operator", "airflow.operators.bash.BashOperator");
taskConfig.put("bash_command", "echo \"Iron task at " + task.getId() + "\"");
}You don't need to manage valid Python code, imports, or Airflow version-specific implementation. This sounds like play, but it demonstrates a serious point:
When orchestration logic becomes configuration, anything that can describe structure can generate pipelines.
The same concept Ada imagined, writing once, reusing infinitely, comes to life through YAML.
Generating Dags from Excel files
At the opposite end of the spectrum is a project built for the office, not the game world. Here, I created a prototype to generate YAML based on an Excel file, allowing me to dynamically generate Dags based on filling out columns and rows within Excel.
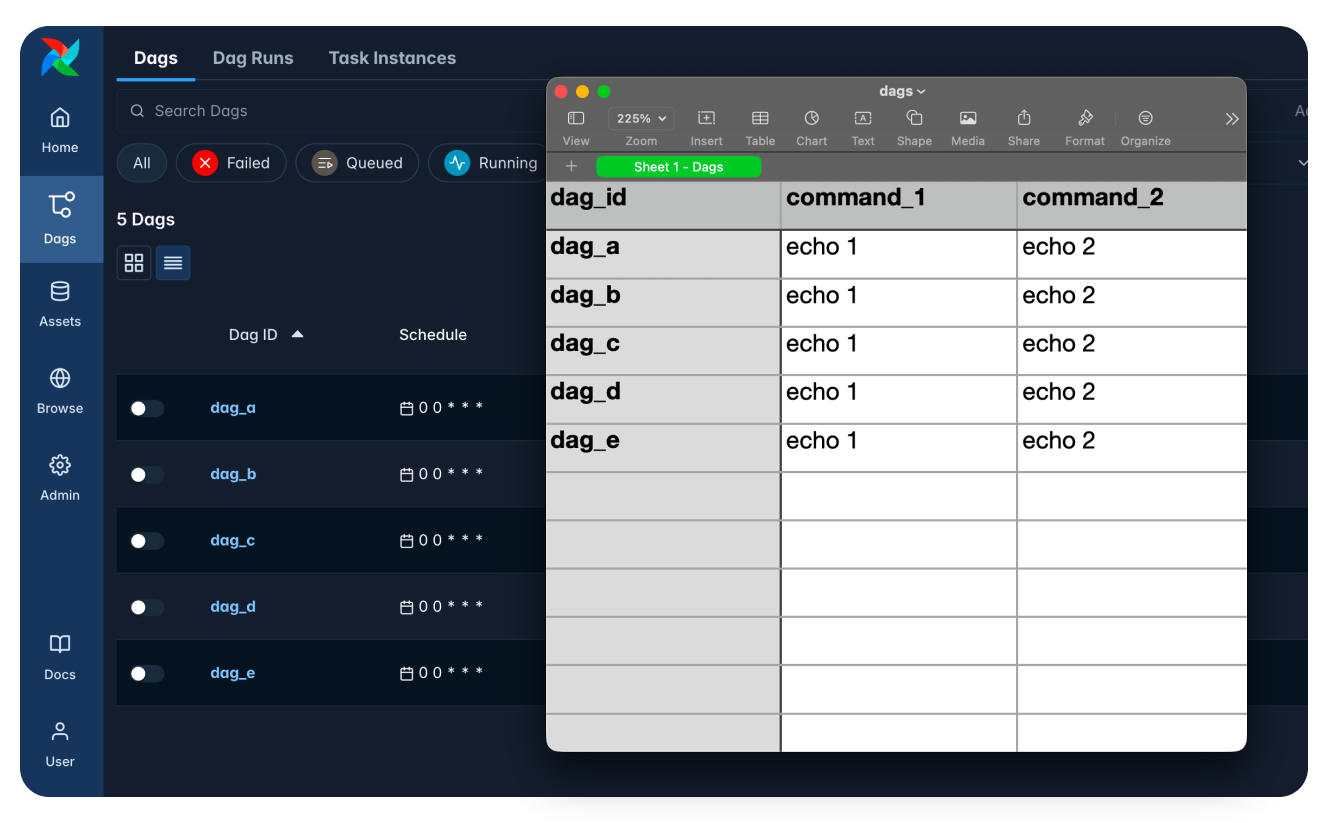
Each row describes a new pipeline. A short Python script then reads the spreadsheet using openpyxl and uses a Jinja template to produce a single YAML file that DAG Factory consumes.
from pathlib import Path
import yaml
from jinja2 import Environment, FileSystemLoader
from openpyxl import load_workbook
TEMPLATE_DIR = "include"
TEMPLATE_FILE = "template.yml"
DAGS_WORKBOOK = "include/xlsx/dags.xlsx"
OUT = "dags/dynamic_dags.yml"
def generate_dags_from_template():
env = Environment(loader=FileSystemLoader(TEMPLATE_DIR), autoescape=True)
template = env.get_template(TEMPLATE_FILE)
workbook = load_workbook(DAGS_WORKBOOK)
sheet = workbook.active
all_dags = {}
for row in sheet.iter_rows(min_row=3):
dag_id = row[0].value
command_1 = row[1].value
command_2 = row[2].value
if not dag_id:
continue
vars = {"dag_id": dag_id, "command_1": command_1, "command_2": command_2}
dag_config = yaml.safe_load(template.render(vars))
all_dags.update(dag_config)
Path(OUT).write_text(yaml.dump(all_dags, sort_keys=False))
if __name__ == "__main__":
generate_dags_from_template()The template.yml defines the structure of the YAML file, with placeholders for the values from the Excel file:
{{ dag_id }}:
tasks:
task_1:
operator: airflow.providers.standard.operators.bash.BashOperator
bash_command: "{{ command_1 }}"
task_2:
operator: airflow.providers.standard.operators.bash.BashOperator
bash_command: "{{ command_2 }}"
dependencies: [task_1]The Excel file can then look like the following:
| dag_id | command_1 | command_2 |
| etl_a | echo extract customers | echo transform data |
| etl_b | echo ingest sales | echo aggregate totals |
Based on this minimum viable product (MVP), a follow-up project could offer different templates per Excel file and even extract SQL logic from Excel to translate it into SQLExecuteQueryOperator instances in the YAML definition.
This example demonstrates that configuration enables adaptability. DAG Factory allows teams to build Dags from whatever input format they already understand.
Scaling orchestration through inheritance
Configuration-based authoring also unlocks standardization at scale.
Imagine an enterprise with several departments, like Marketing, Finance, and Product. Each maintains dozens of pipelines. Every Dag would duplicate owners, retries, and partially even schedules.
DAG Factory supports hierarchical defaults, allowing shared settings to cascade across folders.
# dags/defaults.yml
schedule: "@daily"
default_args:
owner: "data-platform"
retries: 2
start_date: 2025-09-01Department-specific overrides:
# dags/marketing/defaults.yml
schedule: "0 1 * * *"
default_args:
owner: "data-marketing"
# dags/finance/defaults.yml
default_args:
owner: "data-finance"And clean, focused DAGs:
marketing_dag:
tasks:
run_campaign:
operator: airflow.providers.standard.operators.bash.BashOperator
bash_command: "echo running campaign"
finance_dag:
tasks:
close_month:
operator: airflow.providers.standard.operators.bash.BashOperator
bash_command: "echo closing books"No repetition. No drift. Each team inherits global rules while customizing locally. This pattern transforms configuration into governance.
Why this matters
As data platforms mature, the challenge evolves. The bottleneck isn't writing code, it's enabling more people to build pipelines while maintaining quality, consistency, and governance.
Configuration-based authoring can help solve the enablement problem. It lets different roles contribute at their skill level without compromising platform standards.
Traditional code-based orchestration creates a tension: either gate-keep quality through engineers (slow) or let everyone write Python (risky). Configuration-based authoring resolves this tension.
- Engineers build the foundation: robust, tested Python functions that encapsulate business logic. They create reusable components for data extraction, transformation, and quality checks, that become the building blocks others compose into pipelines. This code undergoes proper review, testing, and versioning.
- Analysts build pipelines using these components. Through YAML, Excel, or Minecraft 😉, they declare the workflow: extract from source A, transform with function B, load to destination C. They iterate quickly without writing Python, but they can't bypass the quality controls engineers built into the components.
- Platform teams enforce standards through configuration. Retry policies, timeout settings, alert configurations, these live in shared
defaults.ymlfiles that cascade across teams. Standards become enforceable code, not unread documentation.
This model delivers results because it enables autonomy within guardrails. When orchestration becomes configuration, you enable teams without losing control.
The bridge between paradigms
This was a deep dive for level 2 of the different abstractions we discussed in the first part of this series.


Configuration-based authoring does not replace code-based pipelines, but it complements them. It connects declarative and imperative paradigms. A YAML file, a spreadsheet row, or even a Minecraft structure can all compile into the same Airflow Dag.
Ada Lovelace once imagined a machine that could weave patterns with logic instead of thread. Today, DAG Factory lets us weave workflows the same way, pattern by pattern, configuration by configuration, until orchestration itself becomes art.
Coming next
In the final part of this series, we will explore levels 3 and 4 and discuss how Astro IDE and Blueprint push abstraction even further. Astro IDE brings natural-language Dag authoring directly into the browser, while Blueprint introduces governed, reusable templates that scale orchestration across the enterprise.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.