Pass data between tasks
Info
This page has not yet been updated for Airflow 3. The concepts shown are relevant, but some code may need to be updated. If you run any examples, take care to update import statements and watch for any other breaking changes.
Sharing data between tasks is a very common use case in Airflow. If you’ve been writing DAGs, you probably know that breaking them up into smaller tasks is a best practice for debugging and recovering quickly from failures. What do you do when one of your downstream tasks requires metadata about an upstream task, or processes the results of the task immediately before it?
There are a few methods you can use to implement data sharing between your Airflow tasks. In this guide, you’ll walk through the two most commonly used methods, learn when to use them, and use some example DAGs to understand how they can be implemented.
Other ways to learn
There are multiple resources for learning about this topic. See also:
- Astronomer Academy: Airflow: XComs 101 module.
- Webinar: How to pass data between your Airflow tasks.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Airflow operators. See Operators 101.
- DAG writing best practices. See DAG writing best practices in Apache Airflow.
Best practices
Before you dive into the specifics, there are a couple of important concepts to understand before you write DAGs that pass data between tasks.
Ensure idempotency
An important concept for any data pipeline, including an Airflow DAG, is idempotency. This is the property whereby an operation can be applied multiple times without changing the result. This concept is often associated with your entire DAG. If you execute the same DAGRun multiple times, you will get the same result. However, this concept also applies to tasks within your DAG. If every task in your DAG is idempotent, your full DAG is idempotent as well.
When designing a DAG that passes data between tasks, it’s important that you ensure that each task is idempotent. This helps with recovery and ensures no data is lost if a failure occurs.
Consider the size of your data
Knowing the size of the data you are passing between Airflow tasks is important when deciding which implementation method to use. As you’ll learn, XComs are one method of passing data between tasks, but they are only appropriate for small amounts of data. Large data sets require a method making use of intermediate storage and possibly utilizing an external processing framework.
XCom
The first method for passing data between Airflow tasks is to use XCom, which is a key Airflow feature for sharing task data.
What is XCom
XCom is a built-in Airflow feature. XComs allow tasks to exchange task metadata or small amounts of data. They are defined by a key, value, and timestamp.
XComs can be “pushed”, meaning sent by a task, or “pulled”, meaning received by a task. When an XCom is pushed, it is stored in the Airflow metadata database and made available to all other tasks. Any time a task returns a value (for example, when your Python callable for your PythonOperator has a return), that value is automatically pushed to XCom. Tasks can also be configured to push XComs by calling the xcom_push() method. Similarly, xcom_pull() can be used in a task to receive an XCom.
You can view your XComs in the Airflow UI by going to Admin > XComs. You should see something like this:
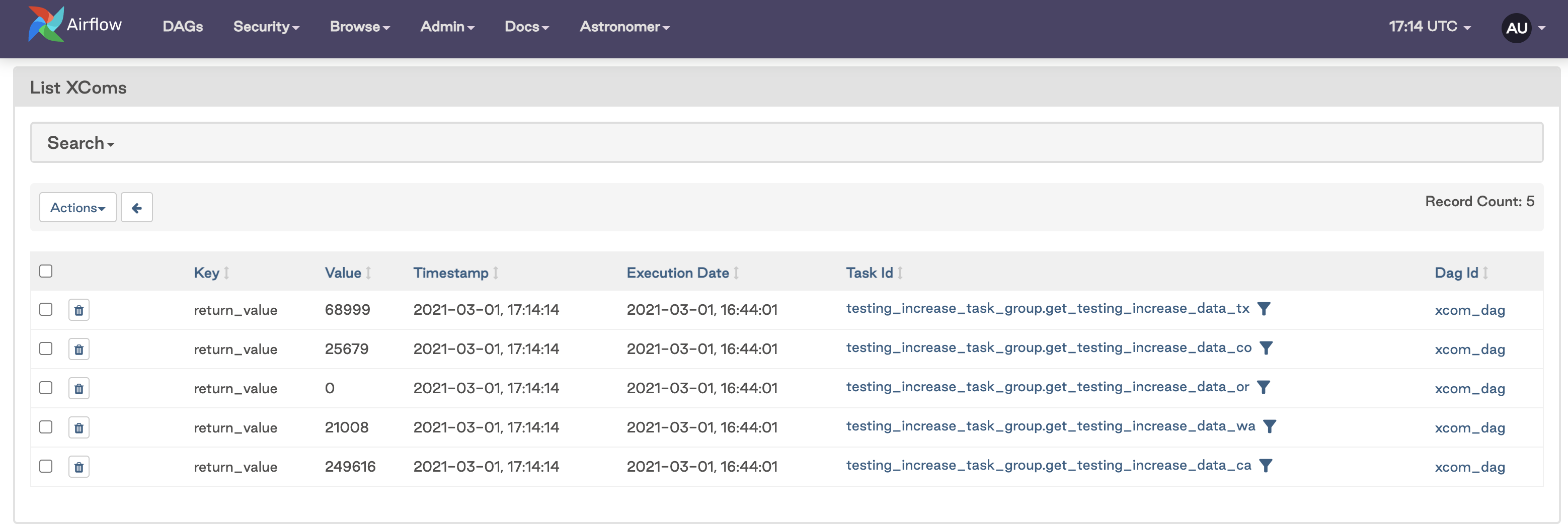
When to use XComs
XComs should be used to pass small amounts of data between tasks. For example, task metadata, dates, model accuracy, or single value query results are all ideal data to use with XCom.
While you can technically pass large amounts of data with XCom, be very careful when doing so and consider using a custom XCom backend and scaling your Airflow resources.
When you use the standard XCom backend, the size-limit for an XCom is determined by your metadata database. Common sizes are:
- Postgres: 1 Gb
- SQLite: 2 Gb
- MySQL: 64 Kb
You can see that these limits aren’t very big. If you think your data passed via XCom might exceed the size of your metadata database, either use a custom XCom backend or intermediary data storage.
The second limitation in using the standard XCom backend is that only certain types of data can be serialized.
By default, Airflow supports serializations for:
- JSON.
- pandas DataFrame (Airflow version 2.6+).
- Delta Lake tables (Airflow version 2.8+).
- Apache Iceberg tables (Airflow version 2.8+).
If you need to serialize other data types you can do so using a custom XCom backend.
Custom XCom backends
Using a custom XCom backend means you can push and pull XComs to and from an external system such as S3, GCS, or HDFS rather than the default of Airflow’s metadata database. You can also implement your own serialization and deserialization methods to define how XComs are handled. To learn how to implement a custom XCom backend using Amazon S3, Google Cloud Storage or Azure blob Storage, follow this step-by-step tutorial.
Example DAG using XComs
In this section, you’ll review a DAG that uses XCom to pass data between tasks. The DAG uses XComs to analyze cat facts that are retrieved from an API. To implement this use case, the first task makes a request to the cat facts API and pulls the fact parameter from the results. The second task takes the results from the first task and performs an analysis. This is a valid use case for XCom, because the data being passed between the tasks is a short string.
Taskflow
You can use the TaskFlow API to push and pull values to and from XCom. To push a value to XCom return it at the end of your task as with traditional operators. To retrieve a value from XCom provide the object created by the upstream task as an input to your downstream task.
Using the TaskFlow API usually requires less code to pass data between tasks than working with the traditional syntax.
Traditional
In this DAG using traditional syntax, there are two PythonOperator tasks which share data using the xcom_push and xcom_pull functions. In the get_a_cat_fact function, the xcom_push method was used to allow the key name to be specified. Alternatively, the function could be configured to return the cat_fact value, because any value returned by an operator in Airflow is automatically pushed to XCom.
For the xcom_pull call in the analyze_cat_facts function, you specify the key and task_ids associated with the XCom you want to retrieve. This allows you to pull any XCom value (or multiple values) at any time into a task. It does not need to be from the task immediately prior as shown in this example.
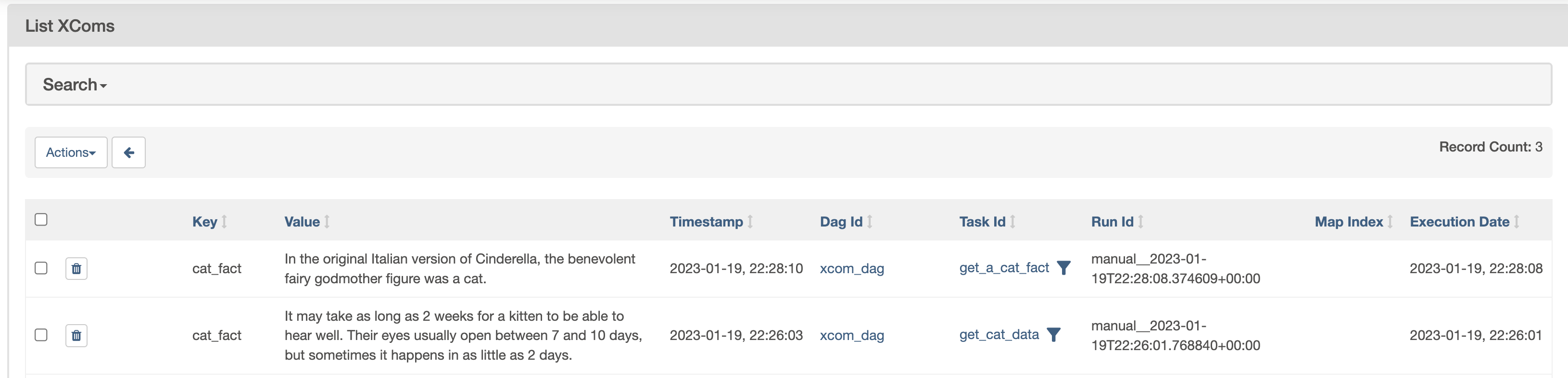
If you run this DAG and then go to the XComs page in the Airflow UI, you’ll see that a new row has been added for your get_a_cat_fact task with the key cat_fact and Value returned from the API.
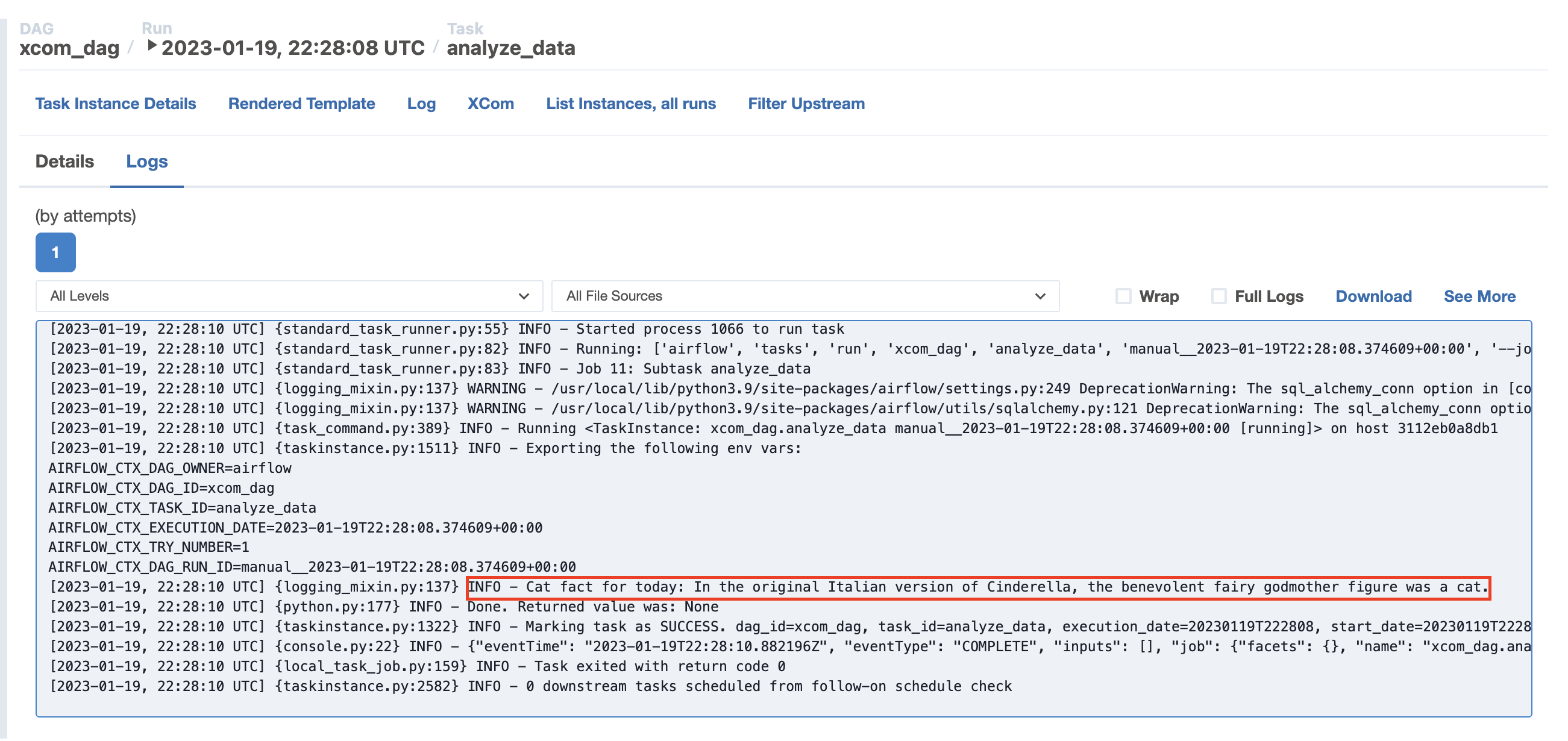
In the logs for the analyze_data task, you can see the value from the prior task was printed, meaning the value was successfully retrieved from XCom.
Intermediary data storage
As mentioned previously, XCom is a great option for sharing data between tasks because it doesn’t rely on any tools external to Airflow itself. However, it is only designed to be used for very small amounts of data. What if the data you need to pass is a little bit larger, for example a small dataframe?
The best way to manage this use case is to use intermediary data storage. This means saving your data to some system external to Airflow at the end of one task, then reading it in from that system in the next task. This is commonly done using cloud file storage such as S3, GCS, or Azure Blob Storage, but it could also be done by loading the data in either a temporary or persistent table in a database.
While this is a great way to pass data that is too large to be managed with XCom, you should still exercise caution. Airflow is meant to be an orchestrator, not an execution framework. If your data is very large, it is probably a good idea to complete any processing using a framework like Spark or compute-optimized data warehouses like Snowflake or dbt.
Example DAG
Building on the previous cat fact example, you are now interested in getting more cat facts and processing them. This case would not be ideal for XCom, but since the data returned is a small dataframe, it can be processed with Airflow.
Taskflow
Traditional
In this DAG you used the S3Hook to save data retrieved from the API to a CSV on S3 in the generate_file task. The process_data task then takes the data from S3, converts it to a dataframe for processing, and then saves the processed data back to a new CSV on S3.