Manage task and task group dependencies in Airflow
Dependencies are a powerful and popular Airflow feature. In Airflow, your pipelines are defined as Directed Acyclic Graphs (DAGs). Each task is a node in the graph and dependencies are the directed edges that determine how to move through the graph. Because of this, dependencies are key to following data engineering best practices because they help you define flexible pipelines with atomic tasks.
Throughout this guide, the following terms are used to describe task dependencies:
- Upstream task: A task that must reach a specified state before a dependent task can run.
- Downstream task: A dependent task that can’t run until an upstream task reaches a specified state.
In this guide you’ll learn about the many ways you can implement dependencies in Airflow, including:
- Basic task dependencies.
- Dependency functions.
- Dynamic dependencies.
- Dependencies with task groups.
- Dependencies with the TaskFlow API.
- Trigger rules.
To view a video presentation of these concepts, see Manage Dependencies Between Airflow Deployments, DAGs, and Tasks.
The focus of this guide is dependencies between tasks in the same DAG. If you need to implement dependencies between DAGs, see Cross-DAG dependencies.
Assumed knowledge
To get the most out of this guide, you should have an understanding of:
- Basic Airflow concepts. See Introduction to Apache Airflow.
Basic dependencies
Basic dependencies between Airflow tasks can be set in the following ways:
- Using bit-shift operators (
<<and>>) - Using the
set_upstreamandset_downstreammethods
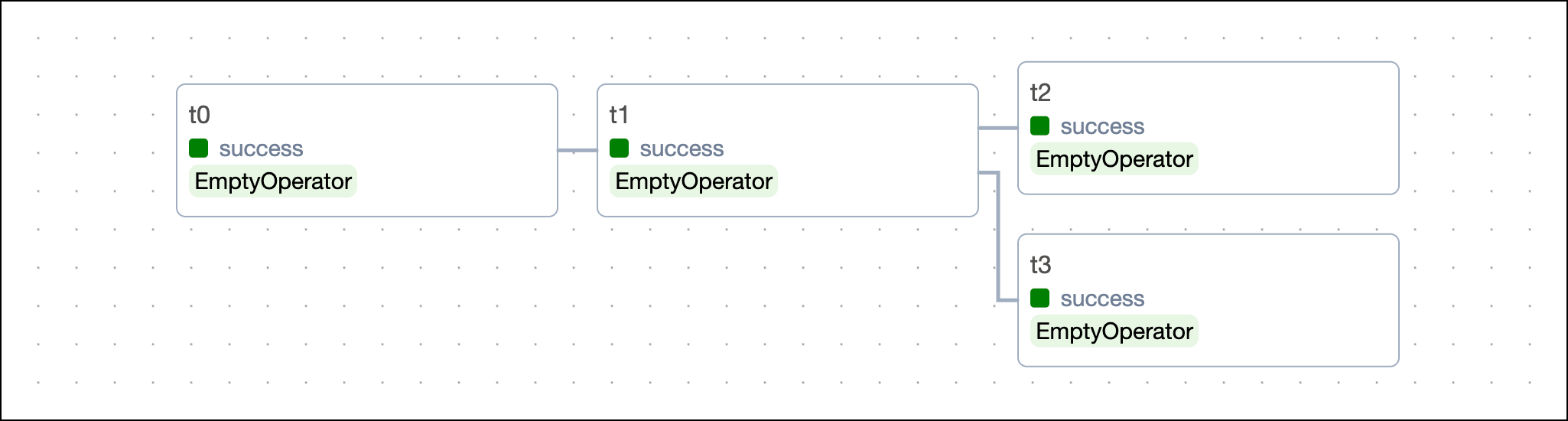
For example, if you have a DAG with four sequential tasks, the dependencies can be set in four ways:
-
Using
set_downstream(): -
Using
set_upstream(): -
Using
>>: -
Using
<<:
All of these methods are equivalent and result in the DAG shown in the following image:

Astronomer recommends using a single method consistently. Using both bit-shift operators and set_upstream/set_downstream in your DAGs can overly complicate your code.
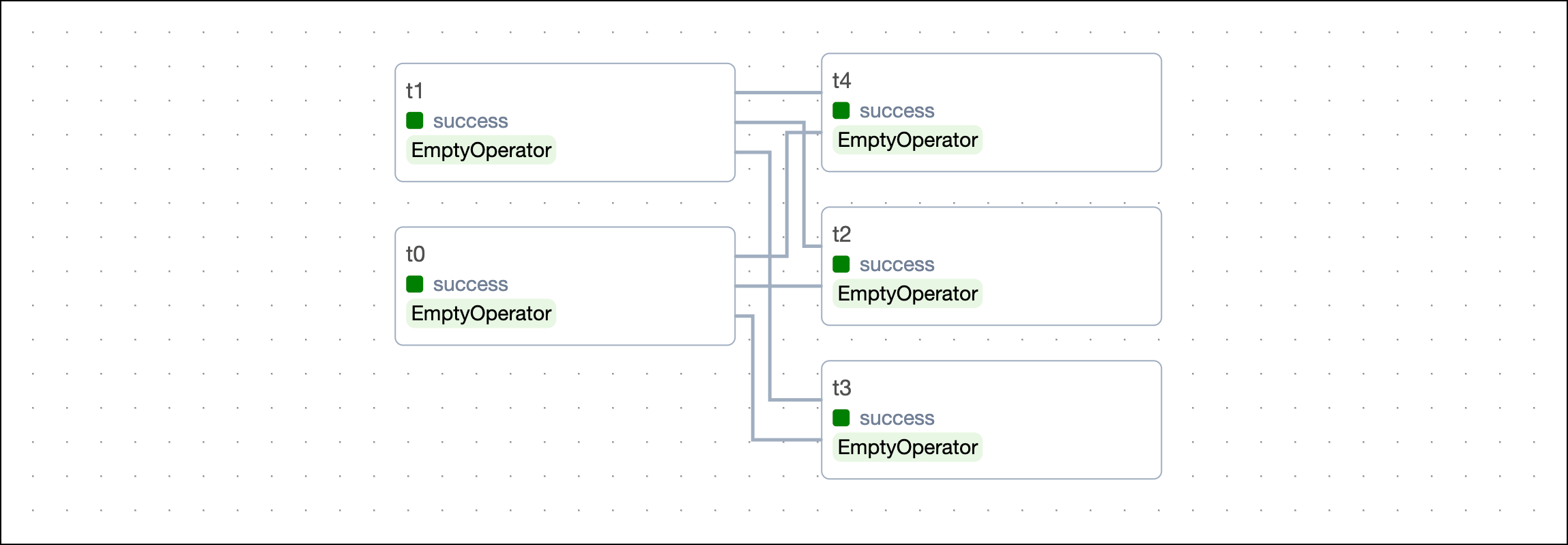
To set a dependency where two downstream tasks are dependent on the same upstream task, use lists or tuples. For example:
These statements are equivalent and result in the DAG shown in the following image:
When you use bit-shift operators and the .set_upstream and .set_downstream method, you can’t set dependencies between two lists. For example, [t0, t1] >> [t2, t3] returns an error. To set dependencies between lists, use the dependency functions described in the following section.
Dependency functions
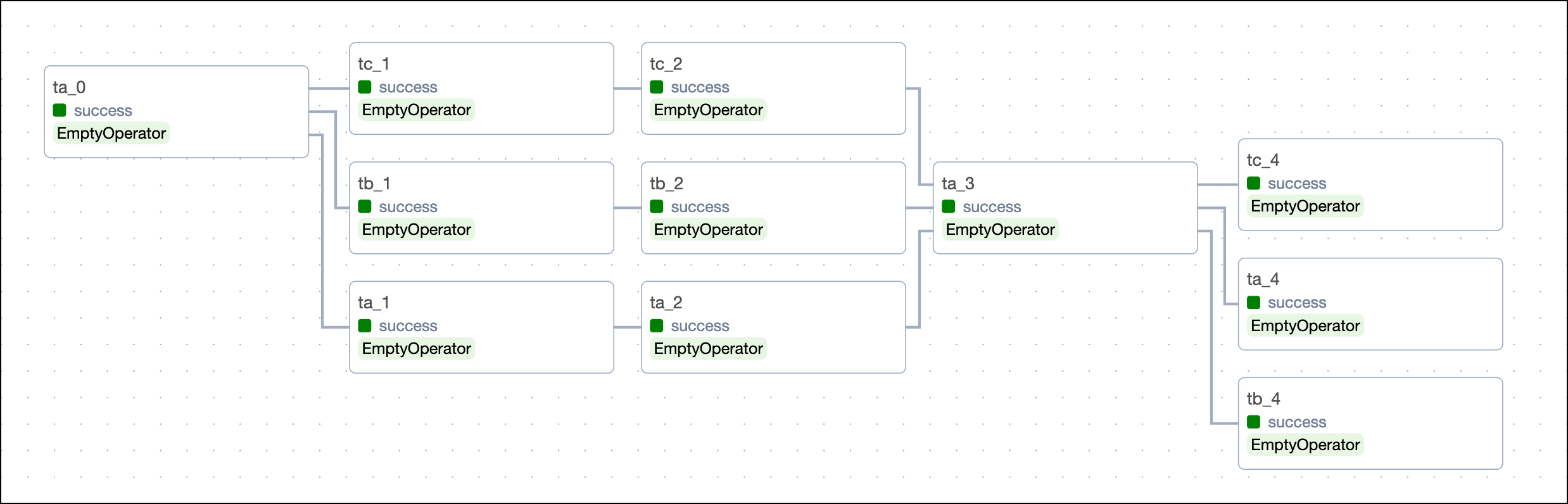
Dependency functions are utilities that let you set dependencies between several tasks or lists of tasks. A common reason to use dependency functions over bit-shift operators is to create dependencies for tasks that were created in a loop and are stored in a list.
This code creates the following DAG structure:
Use chain()
To set parallel dependencies between tasks and lists of tasks of the same length, use the chain() function. For example:
This code creates the following DAG structure:
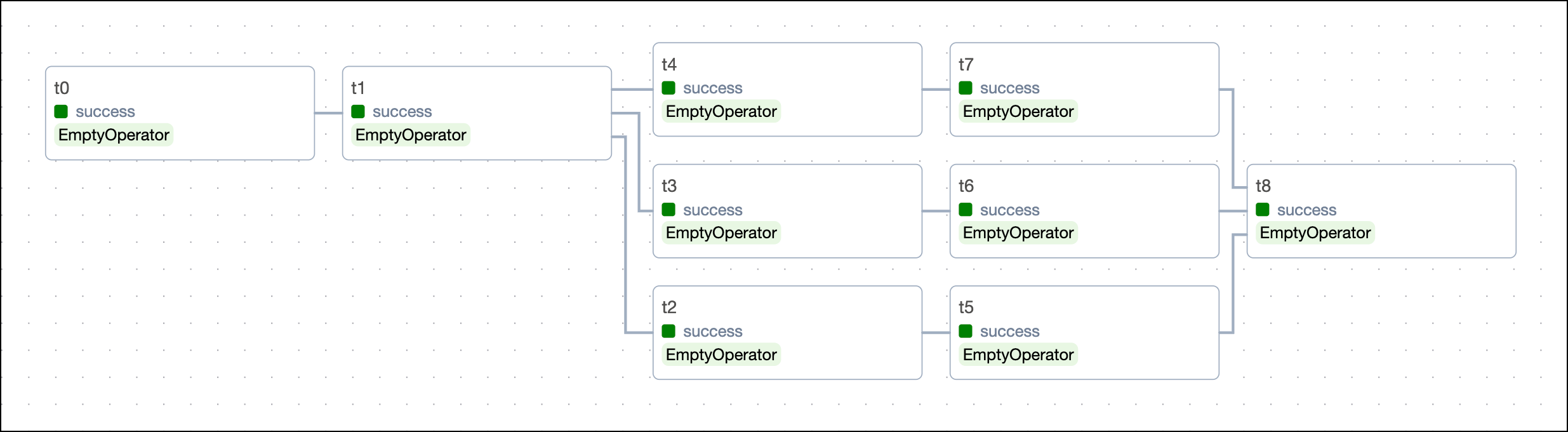
When you use the chain function, any lists or tuples that are set to depend directly on each other need to be the same length.
Use chain_linear()
To set interconnected dependencies between tasks and lists of tasks, use the chain_linear() function.
Replacing chain in the previous example with chain_linear creates dependencies where each element in the downstream list will depend on each element in the upstream list.
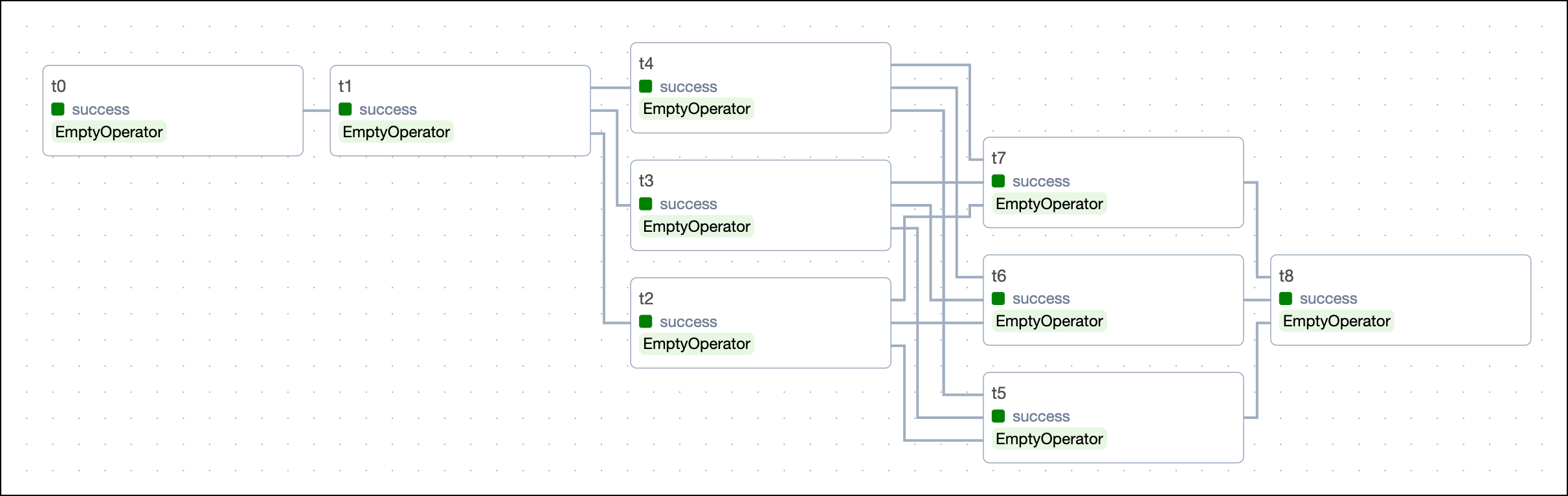
The chain_linear() function can accept lists of any length in any order. For example, the following arguments are valid:
Dependencies in dynamic task mapping
Dependencies for dynamically mapped tasks can be set in the same way as regular tasks. Note that when using the default trigger rule all_success, all mapped task instances need to be successful for the downstream task to run. For the purpose of trigger rules, mapped task instances behave like a set of parallel upstream tasks.
TaskFlow

Traditional

Task group dependencies
Task groups logically group tasks in the Airflow UI and can be mapped dynamically. This section will explain how to set dependencies between task groups.
Dependencies can be set both inside and outside of a task group. For example, in the following DAG code there is a start task, a task group with two dependent tasks, and an end task. All of these tasks need to happen sequentially. The dependencies between the two tasks in the task group are set within the task group’s context (t1 >> t2). The dependencies between the task group and the start and end tasks are set within the DAG’s context (t0 >> tg1() >> t3).
TaskFlow
Traditional
This image shows the resulting DAG:

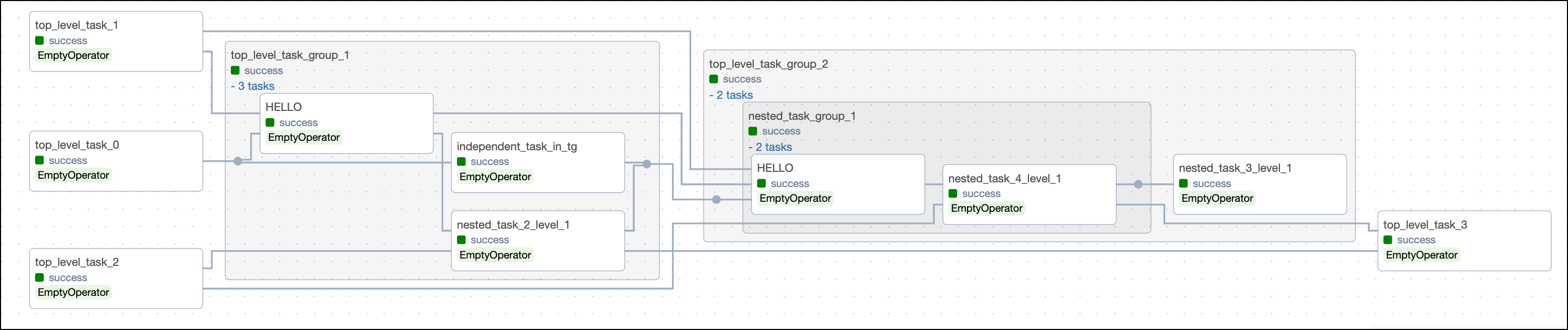
You can also set dependencies between task groups, between tasks inside and out of task groups, and even between tasks in different (nested) task groups.
The image below shows types of dependencies that can be set between tasks and task groups. You can find the code that created this DAG in a GitHub repository both for the TaskFlow API and traditional version.
TaskFlow API dependencies
The TaskFlow API @task decorator allows you to easily turn Python functions into Airflow tasks.
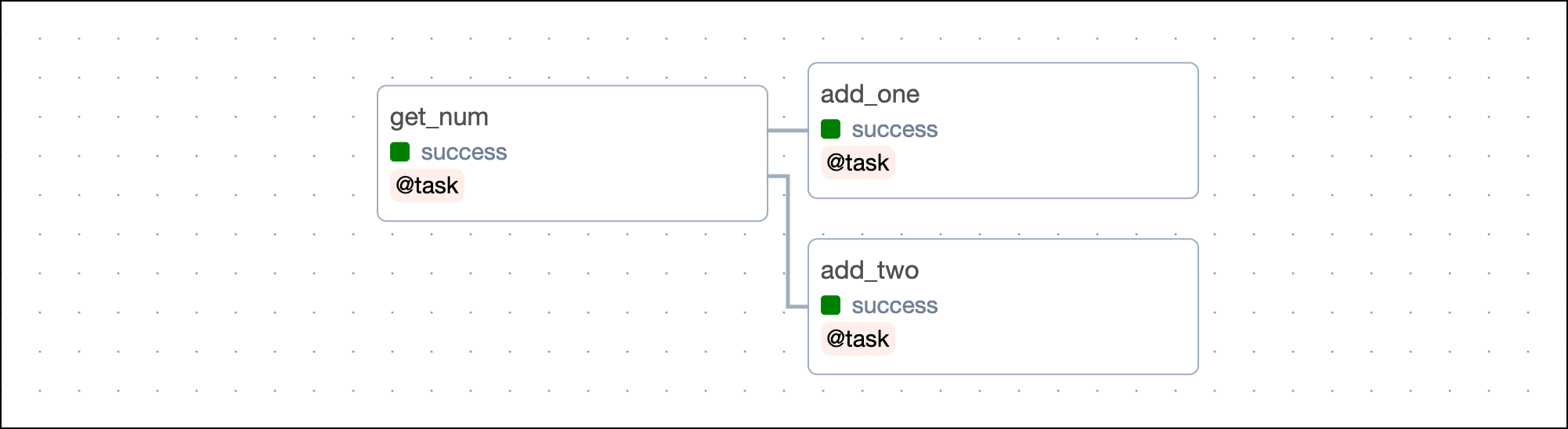
If your DAG has several tasks that are defined with the @task decorator and use each other’s output, you can use inferred dependencies through the TaskFlow API. For example, in the following DAG there are two dependent tasks, get_a_cat_fact and print_the_cat_fact. To set the dependencies, you pass the called function of the upstream task as a positional argument to the downstream task (print_the_cat_fact(get_a_cat_fact())):
This image shows the resulting DAG:

Note that you can also assign the called function to an object and then pass that object to the downstream task. This way of defining dependencies is often easier to read and allows you to set the same task as an upstream dependency to multiple other tasks.
If your DAG contains a mix of Python function tasks defined with decorators and tasks defined with traditional operators, you can set the dependencies by assigning the decorated task invocation to a variable and then defining the dependencies normally. For example, in the DAG below the my_task_1 task is defined by the @task decorator and invoked with _my_task_1 = my_task_1(). The my_task_1 variable is used in the last line to define dependencies.
To learn how to pass information between TaskFlow decorators and traditional tasks, see Mixing TaskFlow decorators with traditional operators.
Trigger rules
When you set dependencies between tasks, the default Airflow behavior is to run a task only when all upstream tasks have succeeded. You can use trigger rules to change this default behavior.
The following options are available:
all_success: (default) The task runs only when all upstream tasks have succeeded.all_failed: The task runs only when all upstream tasks are in a failed or upstream_failed state.all_done: The task runs once all upstream tasks are done with their execution.all_skipped: The task runs only when all upstream tasks have been skipped.one_failed: The task runs when at least one upstream task has failed.one_success: The task runs when at least one upstream task has succeeded.one_done: The task runs when at least one upstream task has either succeeded or failed.none_failed: The task runs only when all upstream tasks have succeeded or been skipped.none_failed_min_one_success: The task runs only when all upstream tasks haven’t failed or upstream_failed, and at least one upstream task has succeeded.none_skipped: The task runs only when no upstream task is in a skipped state.always: The task runs at any time.
Learn more about trigger rules in the Airflow trigger rules guide.