Metrics in Astronomer Software
On Astronomer, metrics generated by StatsD and the Kubernetes API via Prometheus are funneled into a set of Grafana dashboards that allow you to monitor the status of all Airflow Deployments on your cluster.
All dashboards provide real-time, up-to-date information on the status of the Astronomer platform both at the cluster and individual Pod level.
If you're interested in customizing the pre-built dashboards to create other views or compile additional metrics, skip to Creating custom dashboards.
Access Grafana
By default, users with System Admin permissions can access Grafana. To access Grafana from the Software UI:
-
As a System Admin, open Grafana from the Software UI:
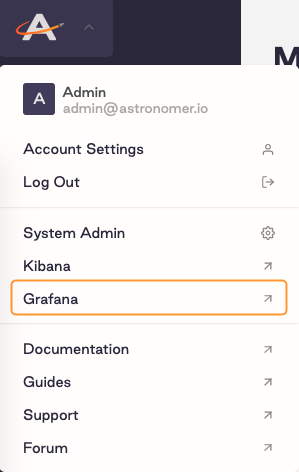
-
Log in to Grafana. If you're on the Welcome page, you can log in via the Sign In button at the bottom of the sidebar menu. The default login credentials are
admin:admin.
-
Click the search button to access all published dashboards.
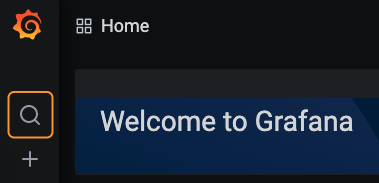
Note: As a System Admin, you can see metrics in Grafana for all Airflow Deployments on your cluster. You do not have to be a member of a Workspace to access Grafana metrics for Deployments within that Workspace.
Filter metrics by Airflow Deployment
Grafana dashboards that display cluster-level metrics often allow you to filter by namespace or Deployment. On Astronomer, every Airflow Deployment has a unique release name that is immutable and corresponds to a Kubernetes namespace. For example, all Pods for a Deployment whose release name is elementary-zenith-7243 run within the astronomer-elementary-zenith-7243 namespace on your cluster. Once you know the release name for a Deployment, you can use it in Grafana to show metrics only for that Deployment.
To filter Grafana metrics by Deployment:
-
In the Software UI, click on a Workspace to see a list of all Deployments in that Workspace.
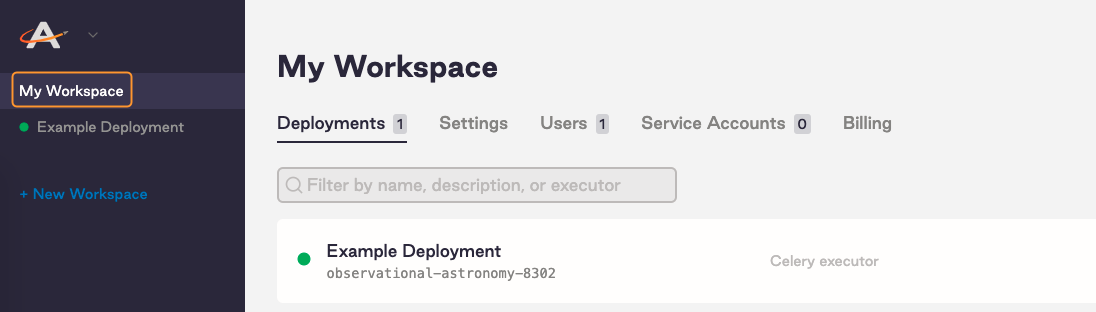
-
The release name for a Deployment is listed under the Deployment's proper name. Make note of the release names for each Deployment you want to monitor.
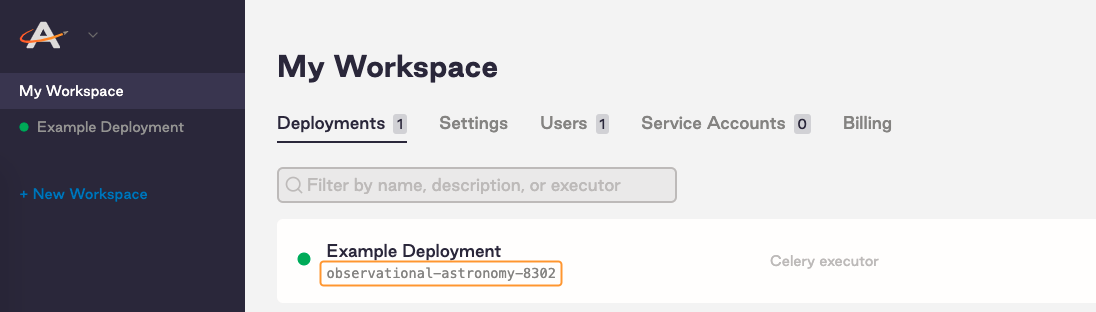
-
In Grafana, open a dashboard. Click the menu under the Deployment's name to see a list of all release names in your cluster. Depending on which dashboard you're using, the name of this menu is either Deployment, Release Name, or Namespace.
-
Select one or multiple release names for the Deployments you want to monitor.
Read the rest of this guide to learn about Astronomer's built-in Grafana dashboards, as well as key metrics for tracking the overall health of your platform.
Platform overview
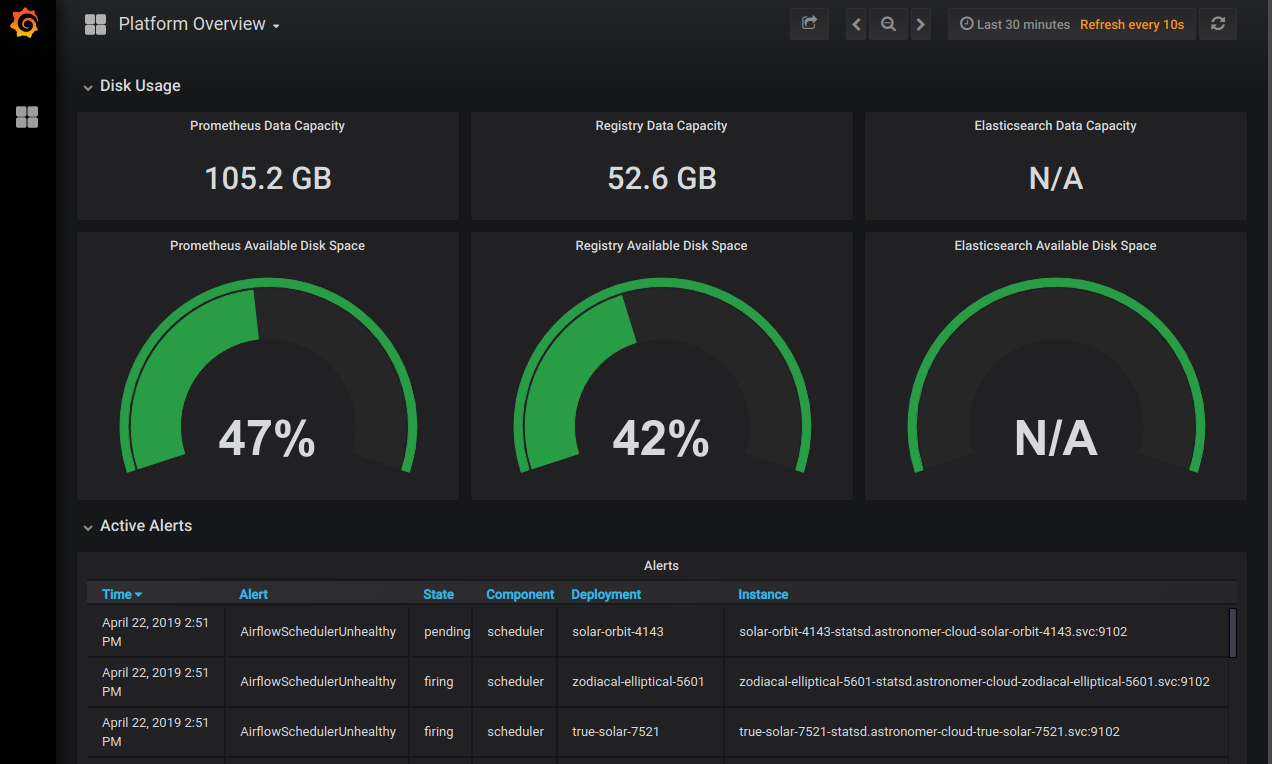
This dashboard shows the amount of persistent storage available to Prometheus, the platform's Docker registry, and Elasticsearch across your entire platform. Use this dashboard to track system-wide behaviors and issues.
Key metrics
-
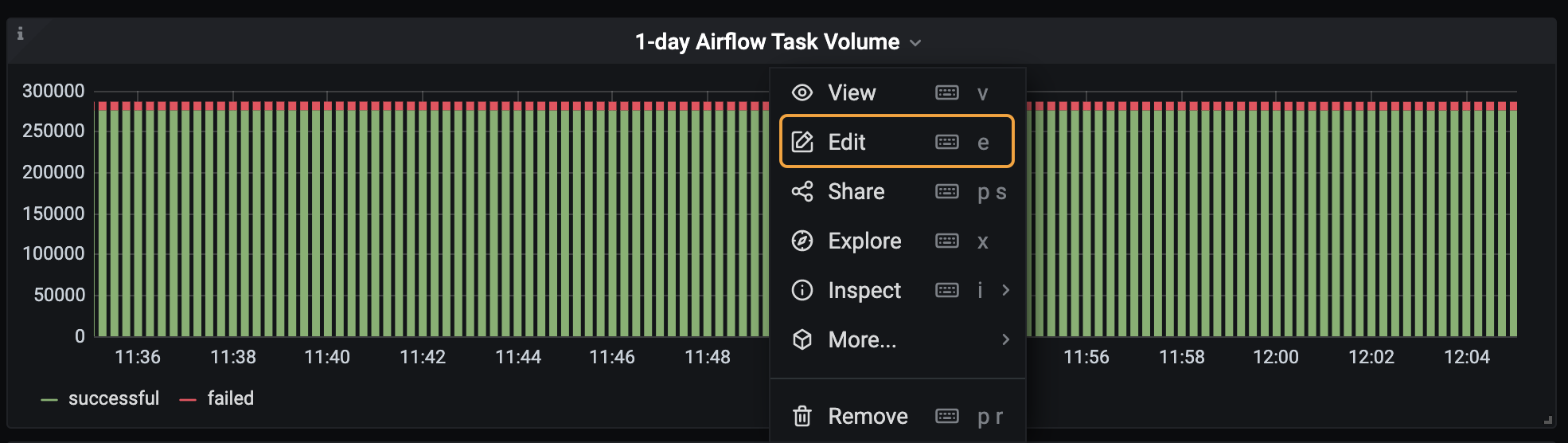
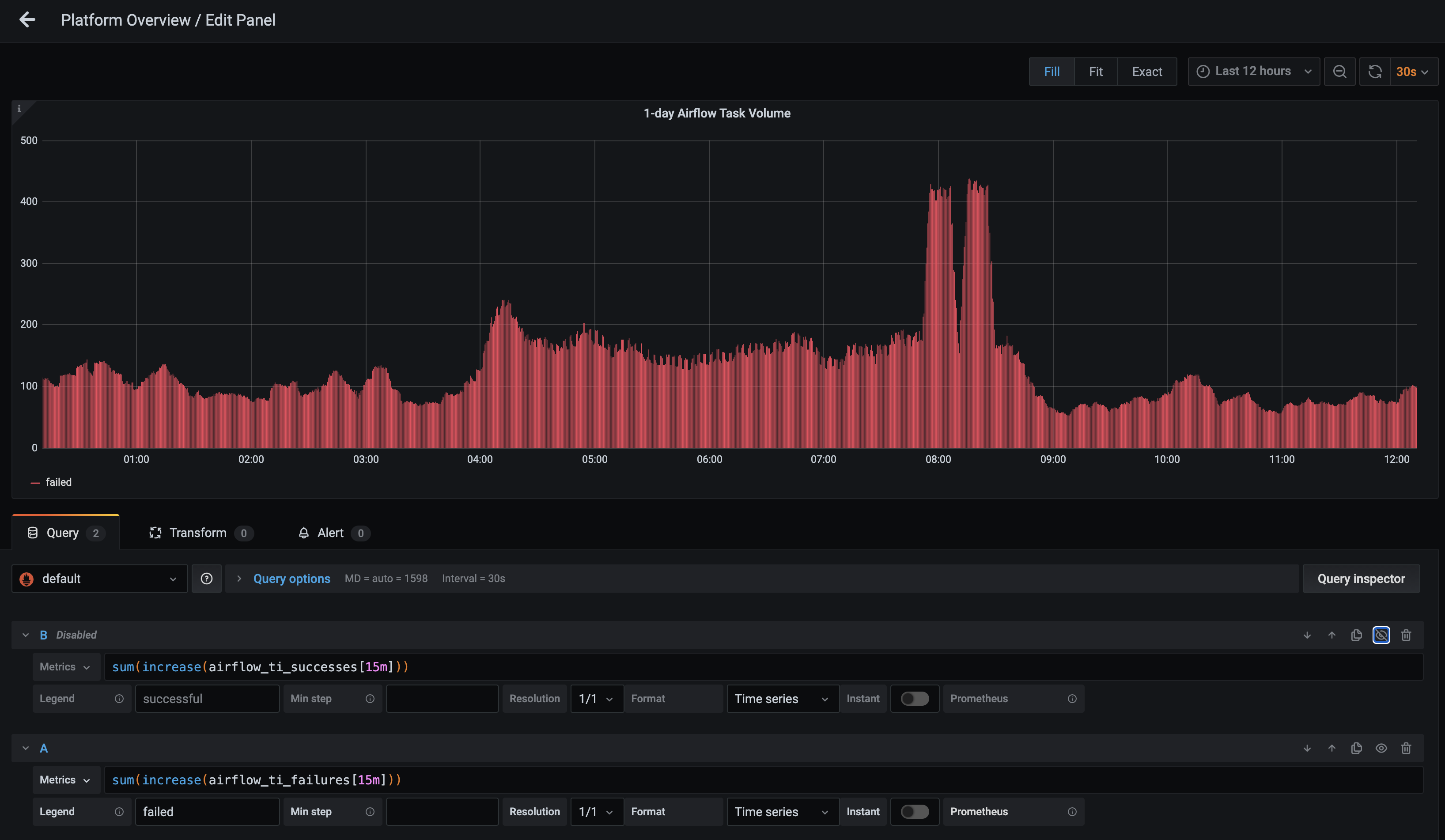
1-day Airflow Task Volume: This metric is the single best tool for monitoring Airflow task successes and failures, as well growth in volume. It can also be adjusted to better find specific data points.
For instance, if you click Edit in the dropdown menu for the metric, you're able to update the Metrics query to show data for a specific time, status, or Deployment.
In the following example, the query has been rewritten in the format
sum(increase(airflow_ti_successes[<time>])), which changes the time interval that appears in the metric. We recommend monitoring across longer intervals to clearly identify trends in task failures and successes: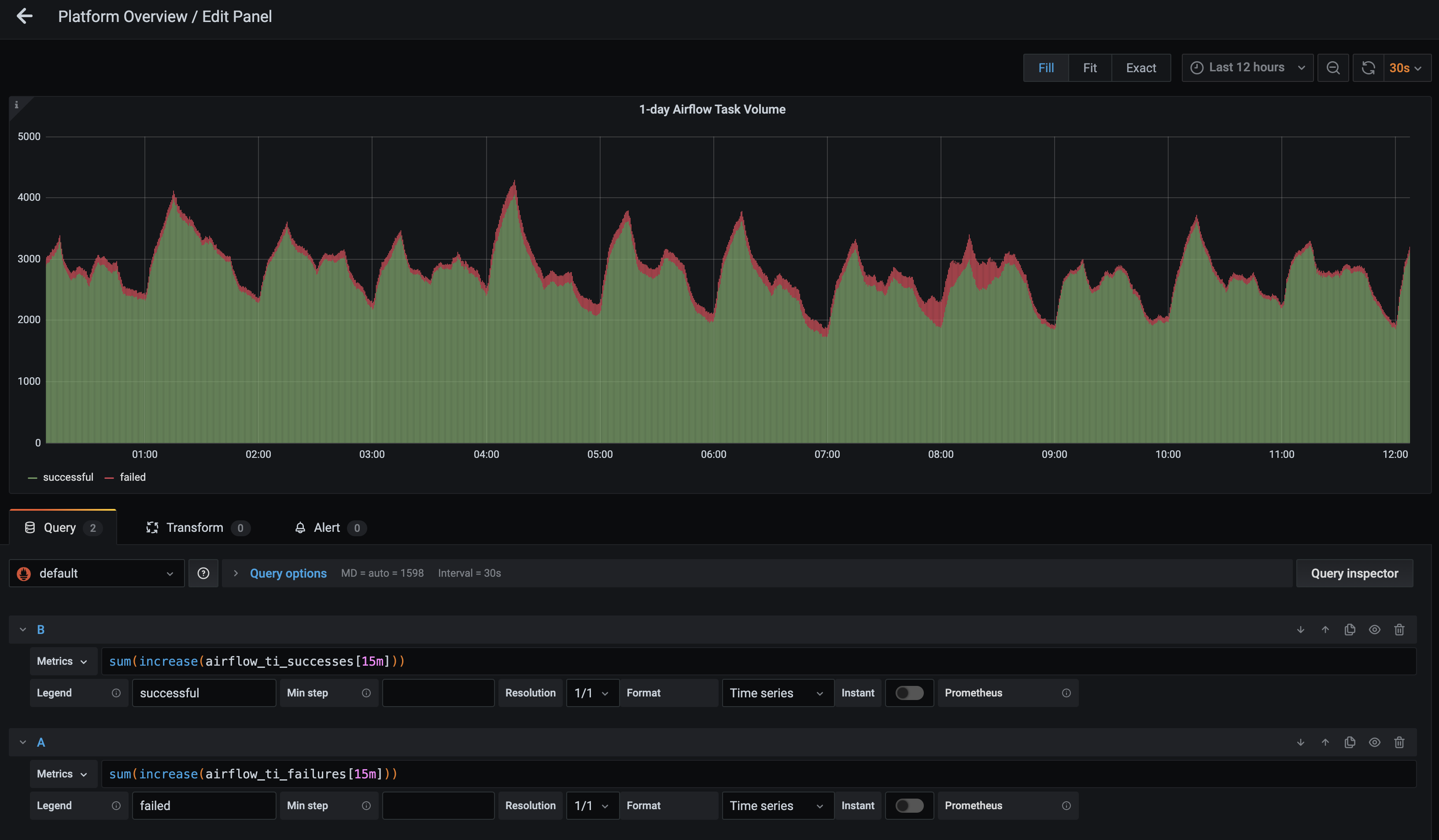
In addition, the eye icon on the metric can be deselected so that only task failures are shown:
You could also write this query as
sum by (deployment) (increase(airflow_ti_failures[<time-interval>]))to view task volume across an entire Deployment, which is useful for monitoring potential system-wide problems: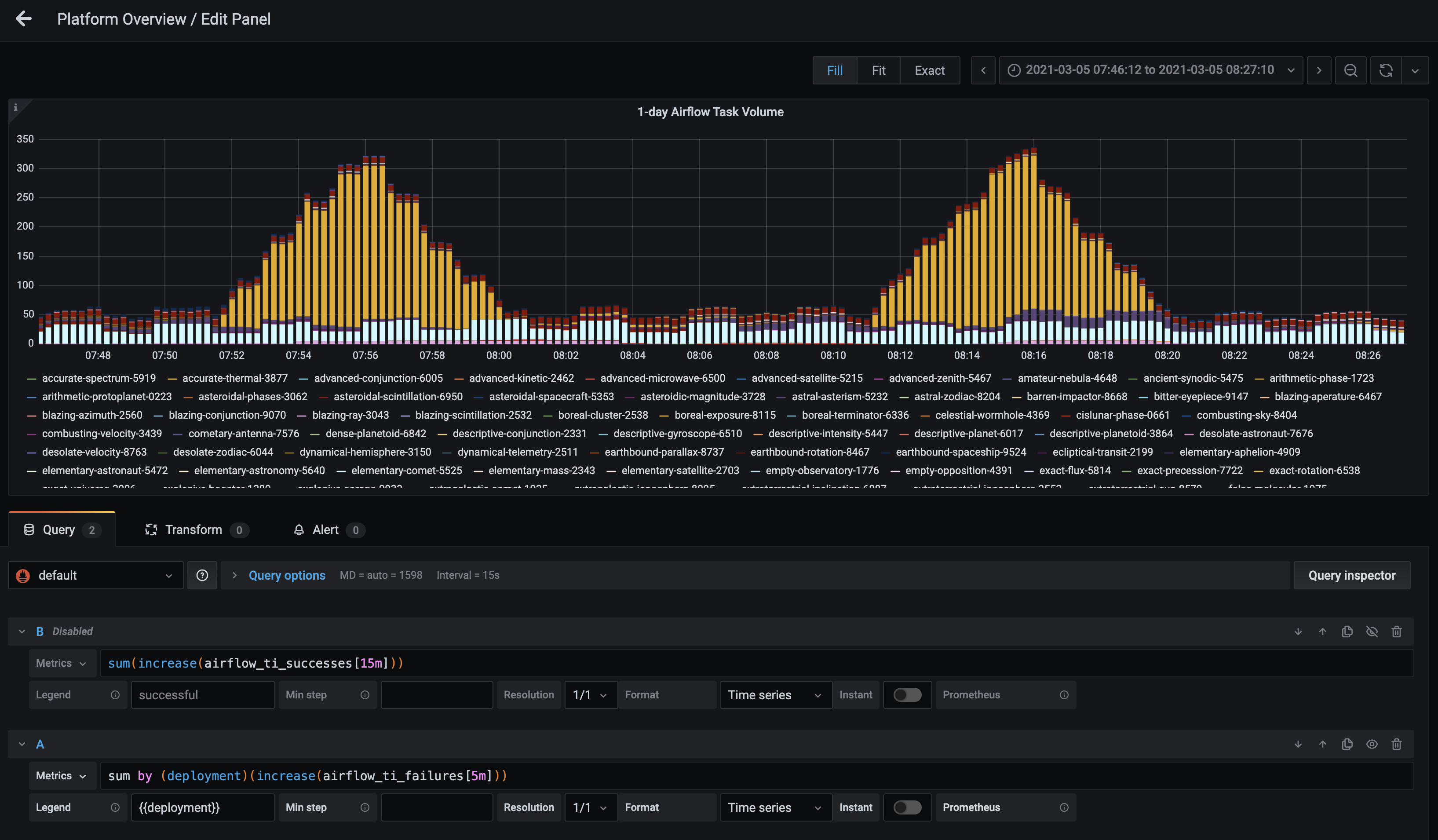
-
Database Connections: This metric can be found in the Database panel. It measures how often your database is reached out to by the Airflow scheduler, webserver, and workers. The chart shows the sum total of connections coming from sqlpooling in all Airflow Deployments in your environment:
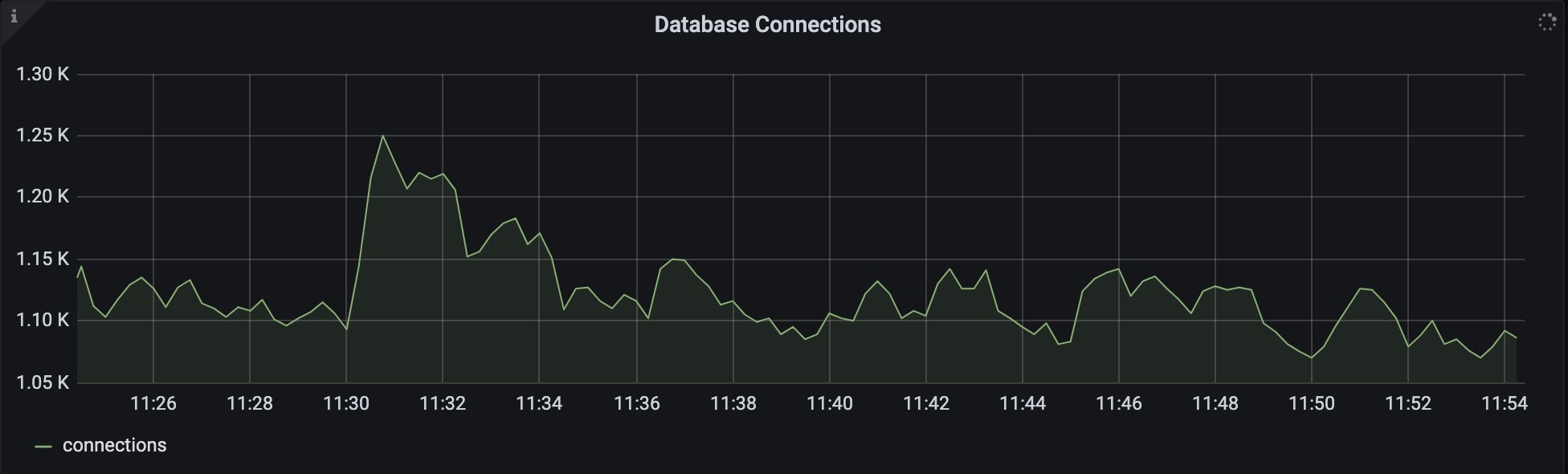
This metric is particularly relevant to organizations with more than 20 Airflow Deployments. For optimal database performance, you should keep this number below
max_connections - 300. -
PG Bouncer Waiting Clients: This metric can be found in the Database panel. It measures how long specific actions are queued in a given Airflow Deployment before being executed. In healthy Deployments, this number should be very low.
Extended periods of waiting can degrade performance and should be investigated for potential problems. For example, the Deployments associated with the red and pink spikes in the following graph might be experiencing issues with successfully executing tasks:
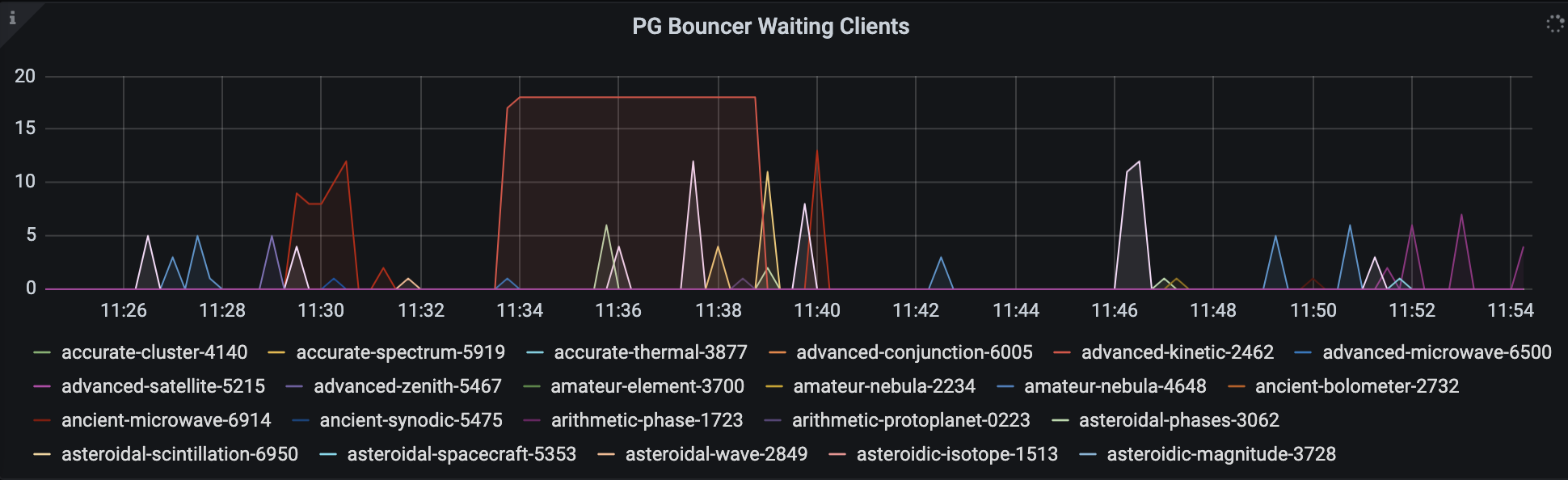
-
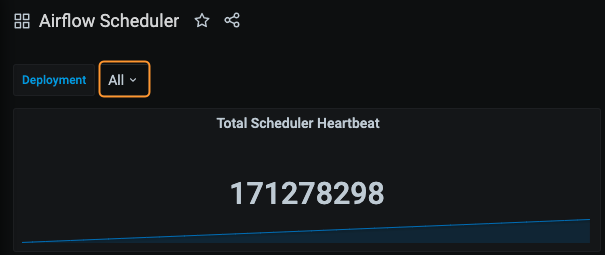
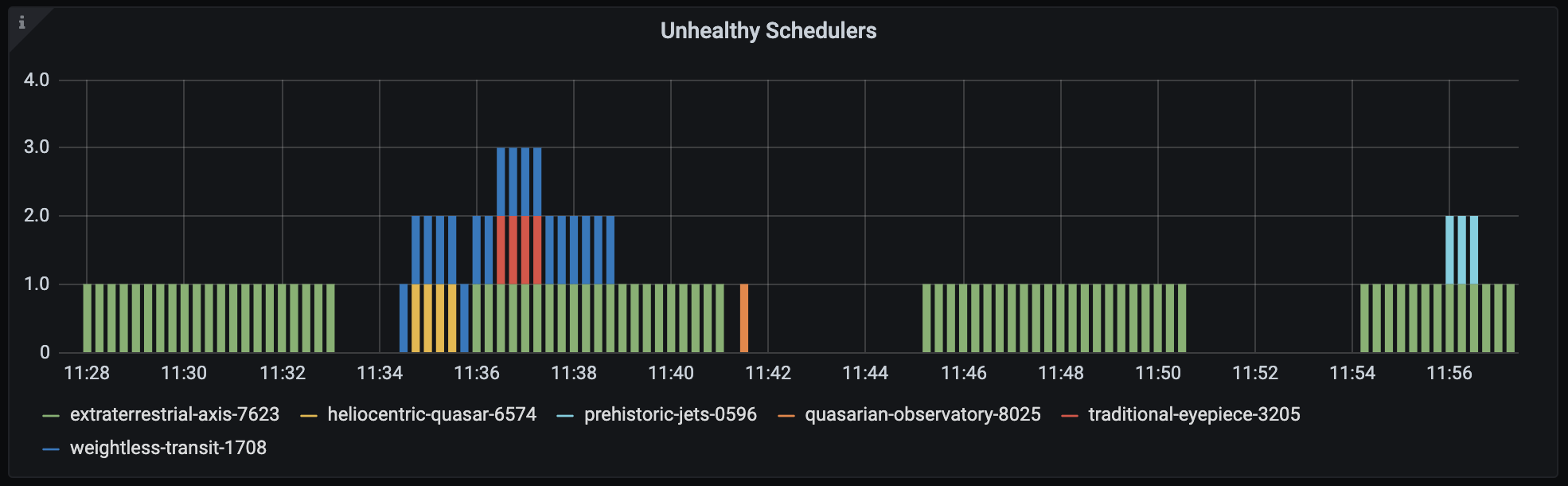
Unhealthy Schedulers: This metric shows the number of unhealthy schedulers in a given Deployment. It's available in the Airflow Health panel, but scheduler health can also be assessed for each individual Deployment in the Metrics tab of the Software UI. A scheduler is considered "Unhealthy" if it has not emitted a heartbeat for over 1 minute.
The lack of a scheduler heartbeat is expected during a code push, but erratic restarts or an "Unhealthy" state that persists for a significant amount of time is worth investigating further.
For example, an organization would want to investigate the green scheduler in the following screenshot:
-
DAG Parsing Time: This metric is available in the Airflow Health panel. It measures how quickly the scheduler is executing your DAGs, and it's an indicator for how well your scheduler is scheduling jobs for execution:
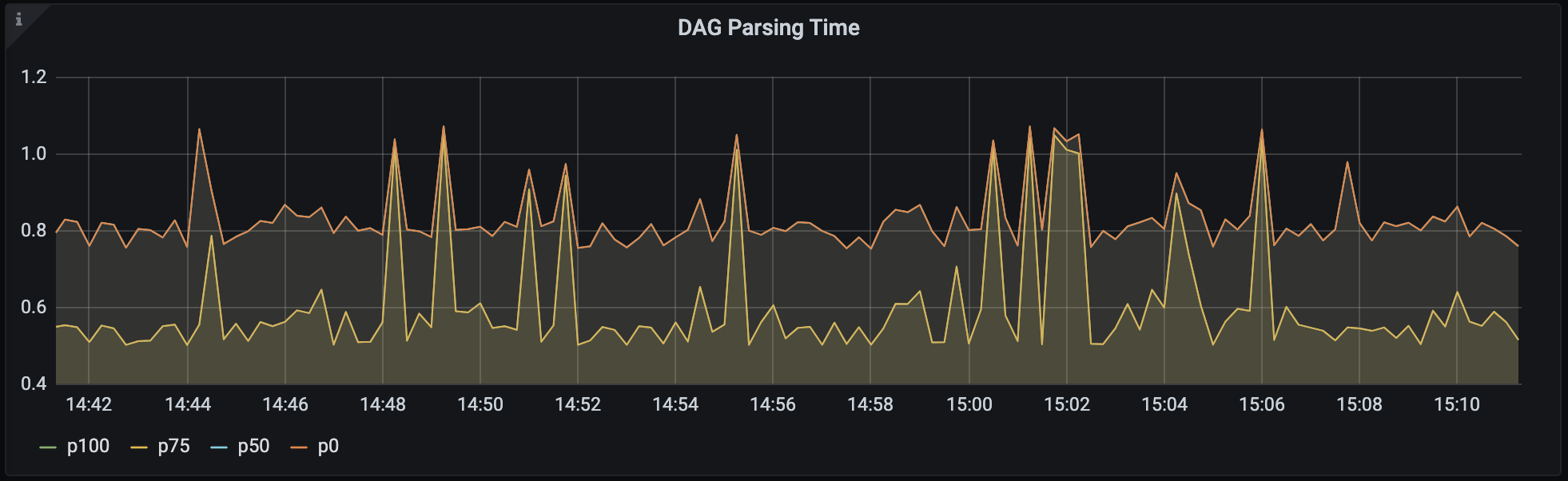
Anything under 1 second is considered good, but the lower the measured time the better. Note that operator executions are not included in this metric, as those are typically scheduled for execution in worker pods.
-
Elasticsearch Available Disk Space: Astronomer utilizes the ELK stack to power logging, an important part of establishing observability for the platform as a whole. To function successfully, Elasticsearch should always have >20% Available Disk Space. You can monitor this from the “Platform Overview” dashboard to ensure that both task and component logs have been successfully captured and persisted:

If this ever dips below 20%, we recommend increasing the replica count in the Elasticsearch Helm chart. The Helm changes will look something like the following:
elasticsearch:
data:
replicas: <number>
Airflow state
This dashboard includes a high-level view of resource usage and system stress levels. Use this dashboard to monitor all Airflow Deployments running within your Kubernetes cluster in a single view.
Key metrics
- CPU Requests and Memory Requests: These metrics appear in the Quotas panel of the dashboard. Most organizations run Astronomer within a cloud environment and pay for resource usage, so it is important to monitor this dashboard and its associated costs. Due to the varying structure, tools, and pricing models of cloud provider solutions, the recommended values for these metrics will vary between organizations.
Kubernetes Pods
This dashboard shows several detailed metrics for each Kubernetes pod in your cluster. If you filter by namespace for a particular Airflow Deployment, you can view a dedicated set of metrics for any pod within that namespace.
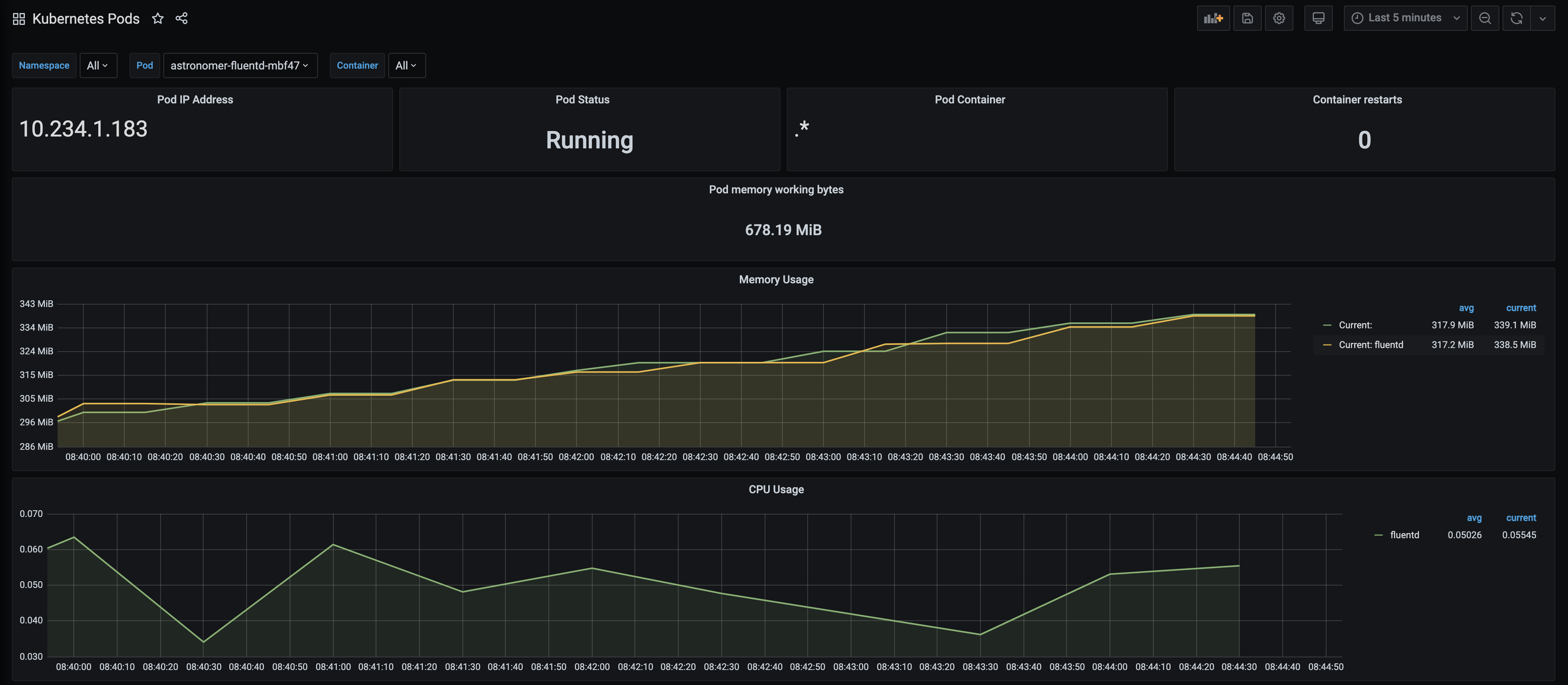
Key metrics
Pod Status: This metric shows the status of a single pod within your cluster, and displays one of 5 states as defined by Kubernetes - Pending, Running, Succeeded, Failed, or Unknown. The value for this metric is equivalent to the output of kubectl get pod <pod-name> -n <namespace>. If you're interested in seeing the status of multiple pods at once, you're free to add a panel to this dashboard.
Airflow Deployment overview
This dashboard shows a set of resource and health-based metrics for individual Deployments. It is most similar to the one displayed in the Metrics tab of the Software UI.
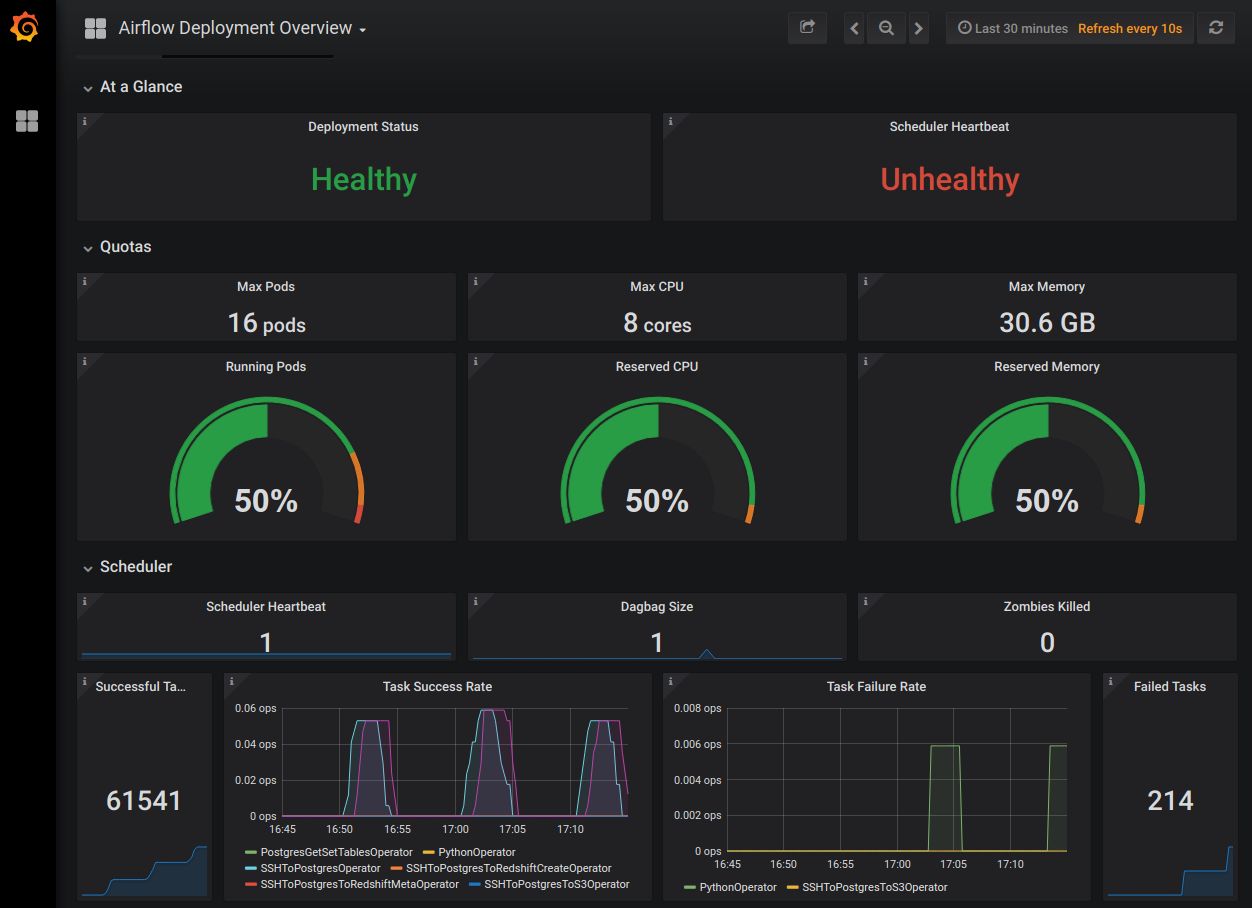
Key metrics
Deployment Status: This metric indicates whether the selected Deployment is "Healthy" or "Unhealthy", as determined by the state of the pods running within it.
If any pod within an Airflow Deployment's namespace is not in a Running state, the Deployment is considered "Unhealthy".
Fluentd
This dashboard tracks the performance of Fluentd, which writes logs to Elasticsearch. You can use the metrics in this dashboard to track the overall status of logs being emitted from the service.
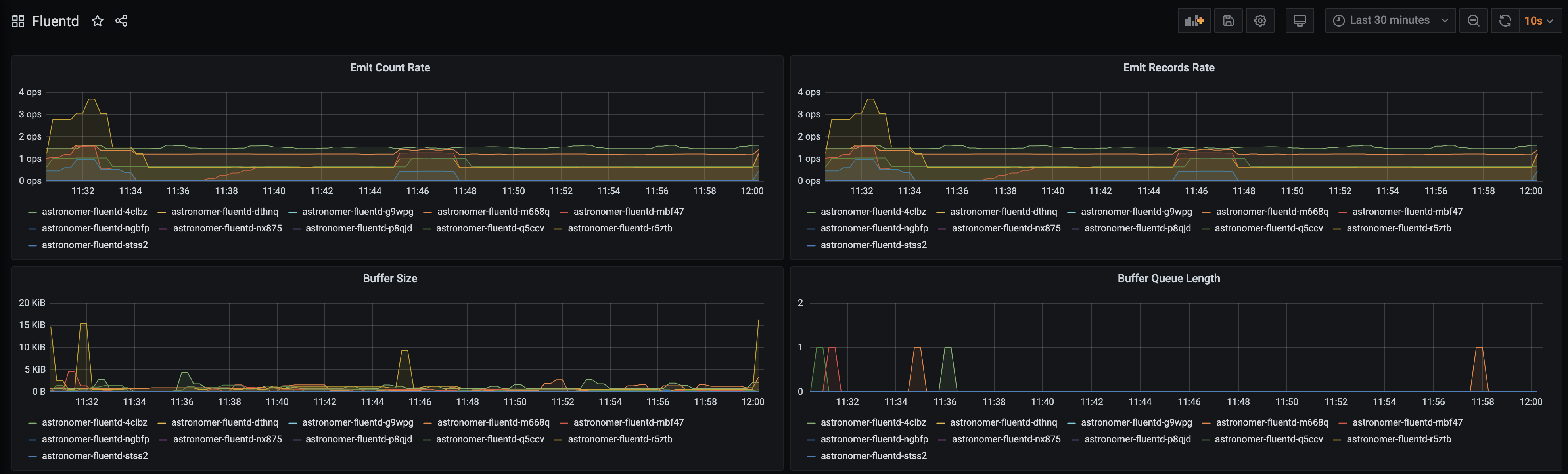
Key metrics
- Buffer Size and Buffer Length: These metrics track whether the Fluentd buffer is backed up, which might indicate an issue with writing logs to Elasticsearch. These metrics should ideally be hovering around zero.
Software UI metrics dashboard
In addition to dashboards in Grafana, each of your Deployments has a built-in metrics dashboard in the Software UI. Any user with access to a given Deployment can access this dashboard. To get there, open a Deployment and go to the Metrics tab:
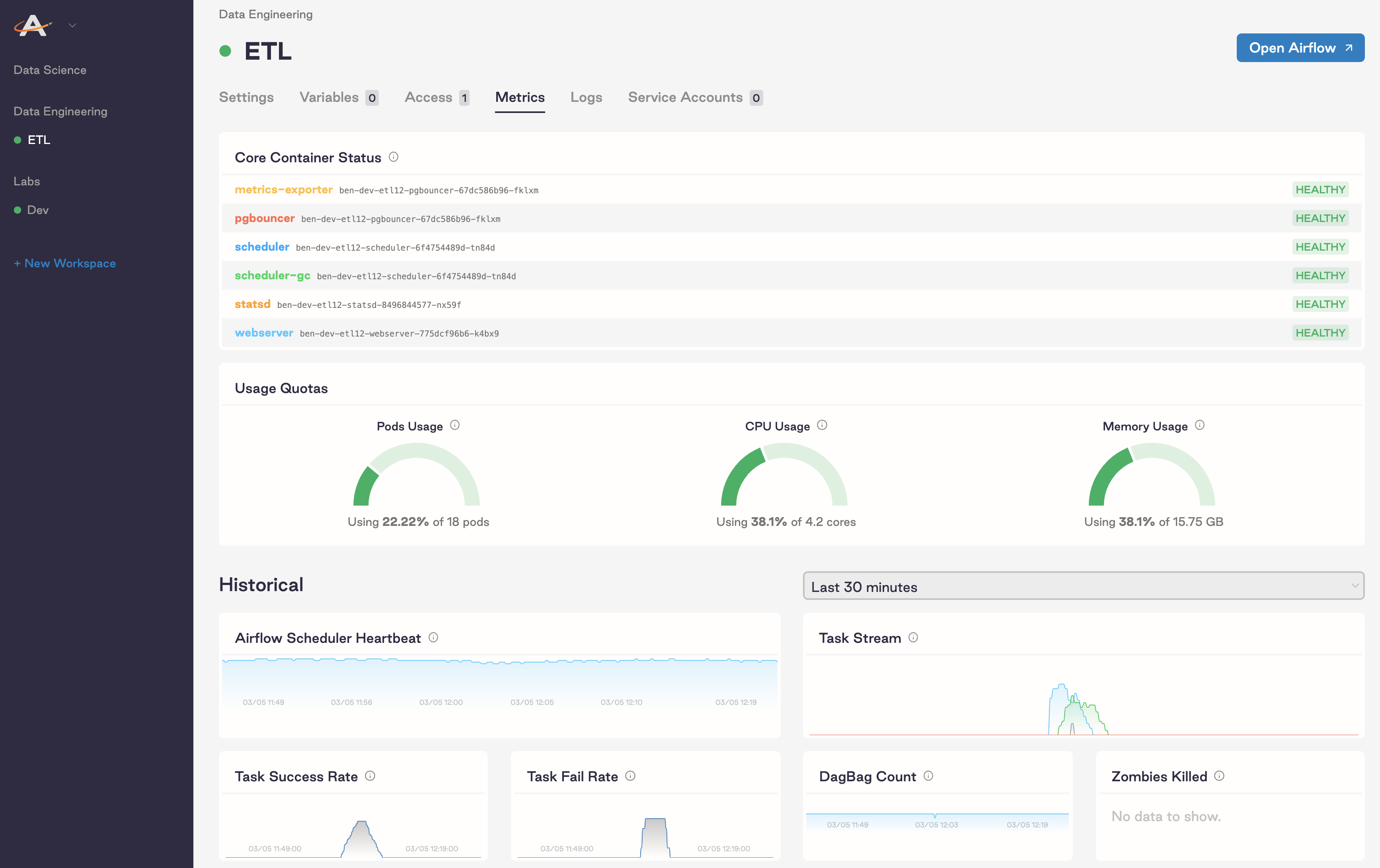
This dashboard is most useful for tracking the performance and resource usage of an individual Airflow Deployment, whereas Grafana is most useful for tracking performance at the platform level and across multiple Airflow Deployments.
Key metrics
-
Usage Quotas: These metrics show the percentage of maximum pods, CPU, and memory an Airflow Deployment is using within its Kubernetes namespace. The upper limit of each metric is pulled from your platform-level configurations for resource quotas.
If you're using the Local or Celery executors, these metrics should each show around 50% usage at all times.
If you're using the Kubernetes executor or the KubernetesPodOperator in your DAGs, these metrics should fluctuate based on the number of tasks you're running at any given time. If any of these numbers reaches its maximum, we recommend allocating more computing power by adjusting the Extra Capacity slider in the Settings tab of your Airflow Deployment.
Create a custom Grafana dashboard
Because Astronomer's key metrics are distributed across several dashboards, you might want to create custom dashboards that compile the metrics you find most important. To create a custom dashboard:
-
As a System Admin, open Grafana from the Software UI.
-
Log in to Grafana. If you're on the Welcome page, you can log in via the Sign In button at the bottom of the sidebar menu. The default login credentials are
admin:admin -
In the Grafana sidebar menu, click the + icon and click Create Dashboard.
-
Specify a visualization type and title for your first panel.
-
In the metric's Query tab, open the data source dropdown menu and select Prometheus.
-
In the table below the data source dropdown menu, specify the metric you want to visualize in the Metrics field.
-
On the top menu, click the Add panel icon to add another panel to the dashboard. Repeat steps 2 and 3 for this panel.
-
Click Save to finalize your changes.
As a starting point, we recommend creating a dashboard with the following metrics visualized as graphs for any organizations using the Kubernetes executor or KubernetesPodOperator in an Airflow Deployment:
- Node Disk Space Utilization
- Node CPU/Memory Utilization
- Disk IO Utilization
- CPU Utilisation
- Memory Utilisation
- CPU Saturation (Load1 per CPU)
- Memory Saturation (Major Page Fails)
- Net Utilisation (Bytes Receive/ Transmit)
- Net Saturation (Drops Receive/Transmit)
These metrics can help you monitor resource usage and subsequent costs of your Kubernetes pods. The recommended steady-state values for these metrics all will be specific to your Kubernetes environment and dependent on available resources/configurations. However, if metrics disappear from this view, it is typically an indication of the node going away and worker pods being relocated to another Kubernetes node.