Run data quality checks using SQL check operators
Info
This page has not yet been updated for Airflow 3. The concepts shown are relevant, but some code may need to be updated. If you run any examples, take care to update import statements and watch for any other breaking changes.
Data quality is key to the success of an organization’s data systems. With in-DAG quality checks, you can halt pipelines and alert stakeholders before bad data makes its way to a production lake or warehouse.
The SQL check operators in the Common SQL provider provide a simple and effective way to implement data quality checks in your Airflow DAGs. Using this set of operators, you can quickly develop a pipeline specifically for checking data quality, or you can add data quality checks to existing pipelines with just a few more lines of code.
This tutorial shows how to use three SQL check operators (SQLColumnCheckOperator, SQLTableCheckOperator, and SQLCheckOperator) to build a robust data quality suite for your DAGs.
Other ways to learn
There are multiple resources for learning about this topic. See also:
- Webinar: Implementing Data Quality Checks in Airflow.
- Webinar: Efficient data quality checks with Airflow 2.7.
- Example repository: data quality demo.
Time to complete
This tutorial takes approximately 30 minutes to complete.
Assumed knowledge
To get the most out of this tutorial, you should have an understanding of:
- How to design a data quality process. See Data quality and Airflow.
- Running SQL from Airflow. See Using Airflow to execute SQL.
Prerequisites
- The Astro CLI.
- Access to a relational database. You can use an in-memory SQLite database for which you’ll need to install the SQLite provider. Note that currently the operators cannot support BigQuery
job_ids. - A love for birds.
Step 1: Configure your Astro project
To use SQL check operators, install the Common SQL provider in your Astro project.
-
Run the following commands to create a new Astro project:
-
Add the Common SQL provider and the SQLite provider to your Astro project
requirements.txtfile.
Step 2: Create a connection to SQLite
-
In the Airflow UI, go to Admin > Connections and click +.
-
Create a new connection named
sqlite_connand choose theSQLiteconnection type. Enter the following information:- Connection Id:
sqlite_conn. - Connection Type:
SQLite. - Host:
/tmp/sqlite.db.
- Connection Id:
Step 3: Add a SQL file with a custom check
-
In your
includefolder, create a file calledcustom_check.sql. -
Copy and paste the following SQL statement into the file:
This SQL statement returns 1 if all combinations of bird_name and observation_year in a templated table are unique, and 0 if not.
Step 4: Create a DAG using SQL check operators
-
Start Airflow by running
astro dev start. -
Create a new file in your
dagsfolder calledsql_data_quality.py. -
Copy and paste the following DAG code into the file:
This DAG creates and populates a small SQlite table
birdswith information about birds. Then, three tasks containing data quality checks are run on the table:-
The
column_checkstask uses theSQLColumnCheckOperatorto run the column-level checks provided to thecolumn_mappingdictionary. The task also uses an operator-levelpartition_clauseto only run the checks on rows where thebird_namecolumn is not null. -
The
table_checkstask uses theSQLTableCheckOperatorto run two checks on the whole table:row_count_check: This check makes sure the table has a least three rows.average_happiness_check: This check makes sure the average happiness of the birds is at least 9. This check has a check-levelpartition_clausewhich means the check only runs on rows with observations from 2021 onwards.
-
The
custom_checktask uses theSQLCheckOperator. This operator can run any SQL statement that returns a single row and will deem the data quality check failed if the that row contains any value Python bool casting evaluates asFalse, for example0. Otherwise, the data quality check and the task will be marked as successful. This task will run the SQL statement in the fileinclude/custom_check.sqlon thetable_namepassed as a parameter. Note that in order to run SQL stored in a file, the path to the SQL file has to be added to thetemplate_searchpathparameter of the DAG.
-
-
Open Airflow at
http://localhost:8080/. Run the DAG manually by clicking the play button, then click the DAG name to view the DAG in the Grid view. All checks are set up to pass.
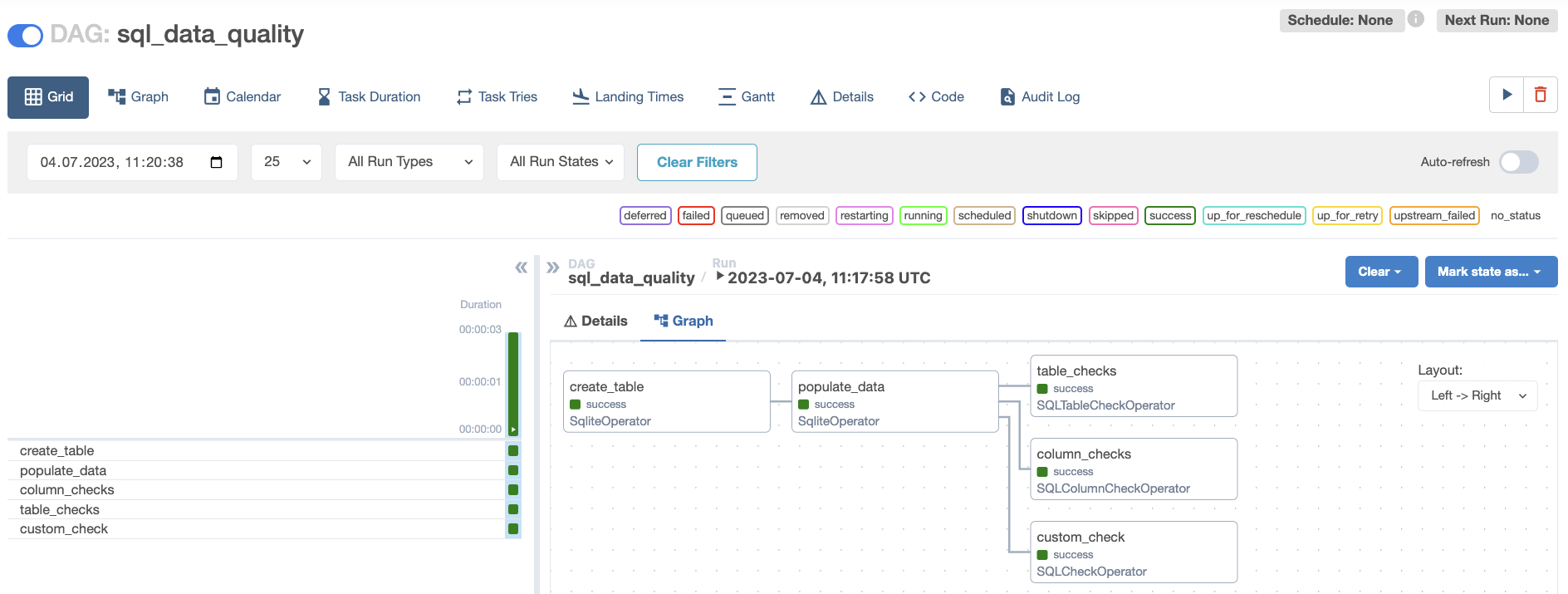
-
View the logs of the SQL check operators to get detailed information about the checks that were run and their results:
For example, the logs for the
column_checkstask show the five individual checks that were run on three columns:
How it works
The SQL check operators abstract SQL queries to streamline data quality checks. One difference between the SQL check operators and the standard BaseSQLOperator is that the SQL check operators respond with a boolean, meaning the task fails when any of the resulting queries fail. This is particularly helpful for stopping a data pipeline before bad data makes it to a given destination. The lines of code and values that fail the check are observable in the Airflow logs.
The following SQL check operators are recommended for implementing data quality checks:
SQLColumnCheckOperator: Runs one or more predefined data quality checks on one or more columns within the same task.SQLTableCheckOperator: Runs multiple user-defined checks which can involve one or more columns of a table.SQLCheckOperator: Takes any SQL query and returns a single row that is evaluated to booleans. This operator is useful for more complicated checks that could span several tables of your database.SQLIntervalCheckOperator: Checks current data against historical data.
Astronomer recommends using the SQLColumnCheckOperator and SQLTableCheckOperator over the older operators (SQLValueCheckOperator and SQLThresholdCheckOperator) whenever possible to improve code readability.
SQLColumnCheckOperator
The SQLColumnCheckOperator has a column_mapping parameter which stores a dictionary of checks. Using this dictionary, it can run many checks within one task and still provide observability in the Airflow logs over which checks passed and which failed.
This operator is useful for:
- Ensuring all numeric values in a column are above a minimum, below a maximum or within a certain range (with or without a tolerance threshold).
- Null checks.
- Checking primary key columns for uniqueness.
- Checking the number of distinct values of a column.
The SQLColumnCheckOperator offers 5 options for column checks which are abstractions over SQL statements:
- “min”:
"MIN(column) AS column_min" - “max”:
"MAX(column) AS column_max" - “unique_check”:
"COUNT(column) - COUNT(DISTINCT(column)) AS column_unique_check" - “distinct_check”:
"COUNT(DISTINCT(column)) AS column_distinct_check" - “null_check”:
"SUM(CASE WHEN column IS NULL THEN 1 ELSE 0 END) AS column_null_check"
The resulting values can be compared to an expected value using any of the following qualifiers:
greater_thangeq_to(greater or equal than)equal_toleq_to(lesser or equal than)less_than
Additionally, the SQLColumnCheckOperator:
- Allows you to specify a tolerance to the comparisons as a fraction (0.1 = 10% tolerance), see the partition_clause section for an example.
- Converts a returned
resultofNoneto 0 by default and still runs the check. For example, if a column check for theMY_COLcolumn is set to accept a minimum value of -10 or more but runs on an empty table, the check would still pass because theNoneresult is treated as 0. You can toggle this behavior by settingaccept_none=False, which will cause all checks returningNoneto fail. - Accepts an operator-level
partition_clauseparameter that allows you to run checks on a subset of your table. See the partition_clause section for more information.
SQLTableCheckOperator
The SQLTableCheckOperator provides a way to check the validity of user defined SQL statements which can involve one or more columns of a table. There is no limit to the amount of columns these statements can involve or to their complexity. The statements are provided to the operator as a dictionary with the checks parameter.
The SQLTableCheckOperator is useful for:
- Checks that include aggregate values using the whole table (e.g. comparing the average of one column to the average of another using the SQL
AVG()function). - Row count checks.
- Checking if a date is between certain bounds (for example, using
MY_DATE_COL BETWEEN '2019-01-01' AND '2019-12-31'to make sure only dates in the year 2019 exist). - Comparisons between multiple columns, both aggregated and not aggregated.
Similarly to the SQLColumnCheckOperator, you can pass a SQL WHERE-clause (without the WHERE keyword) to the operator-level partition_clause parameter or as a check-level partition_clause.
SQLCheckOperator
The SQLCheckOperator returns a single row from a provided SQL query and checks to see if any of the returned values in that row are a value that Python bool casting evaluates as False, for example 0. If any values are False, the task fails. This operator lets you check:
- A specific, single column value.
- Part of or an entire row compared to a known set of values.
- Options for categorical variables and data types.
- Comparisons between multiple tables.
- The results of any other function that can be written as a SQL query.
The target table(s) for the SQLCheckOperator has to be specified within the SQL statement. The sql parameter of this operator can be either a complete SQL query as a string or, as in this tutorial, a reference to a query stored in a local file.
partition_clause
With the SQLColumnCheckOperator and SQLTableCheckOperator, you can run checks on a subset of your table using either a check-level or task-level partition_clause parameter. This parameter takes a SQL WHERE-clause (without the WHERE keyword) and uses it to filter your table before running a given check or group of checks in a task.
The code snippet below shows a SQLColumnCheckOperator defined with a partition_clause at the operator level, as well as a partition_clause in one of the two column checks defined in the column_mapping.
In the following example, the operator checks whether:
MY_NUM_COL_1has a minimum value of 10 with a tolerance of 10%, meaning that the check will pass if the minimum value in this column is between 9 and 11.MY_NUM_COL_2has a maximum value less than 300. Only rows that fulfill the check-levelpartition_clauseare checked (rows whereCUSTOMER_STATUS = 'active').
Both of the above checks only run on rows that fulfill the operator-level partition clause CUSTOMER_NAME IS NOT NULL. If both an operator-level partition_clause and a check-level partition_clause are defined for a check, the check will only run on rows fulfilling both clauses.